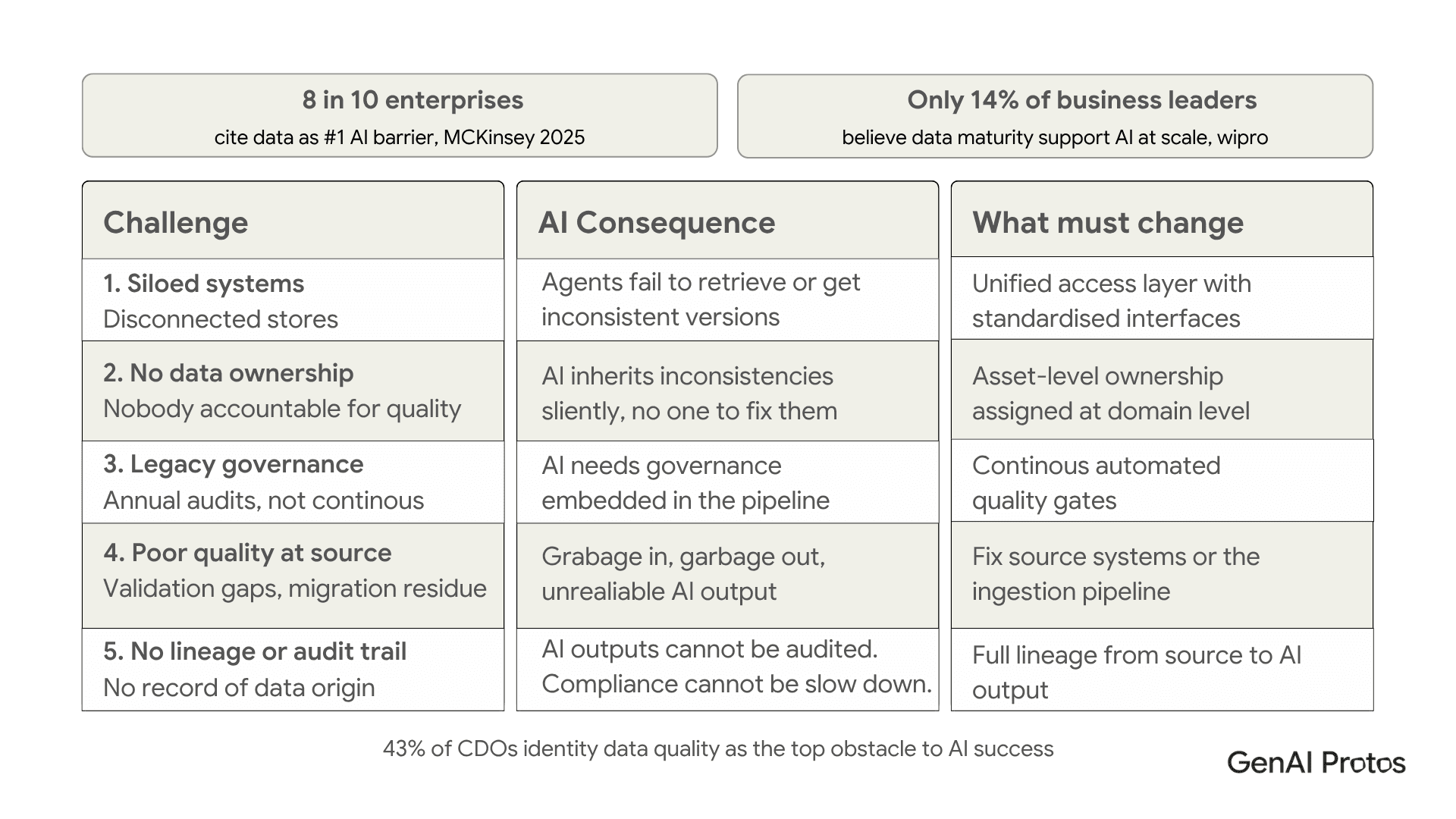
Recent research found that eight in ten enterprises cite data limitations as their primary barrier to scaling AI. Not model quality. Not compute costs. Not talent. Data.
This lines up with what data leaders consistently report 43% identify data quality and readiness as the top obstacle to AI success. The scale of the problem is even starker when you look at maturity: only 14% of business leaders believe their data environment can support AI at scale.
These numbers explain a pattern that appears repeatedly in enterprise AI delivery: a well-chosen model, a sound architecture, a clear business case and then a stall, because the data underneath it was never built for what the AI needs to do.
The uncomfortable truth: your AI is only as good as your data
Vendor demonstrations of AI systems almost always run on curated, clean, controlled datasets. Production systems run on years of accumulated enterprise data created for different purposes, stored in incompatible formats, and never intended to train or ground an AI model.
The gap between demo performance and production performance is, in almost every case, a data gap. When AI systems produce unreliable outputs, when agentic workflows lose coherence mid-process, when RAG-based applications retrieve irrelevant context the root cause is nearly always the quality, structure, or accessibility of the underlying data. The model did not fail. The data did.
What a data foundation for AI actually is
A data foundation for AI is not a data warehouse. It is not a data lake. It is not a reporting infrastructure. Those are components, but they are not sufficient.
An AI data management platform built for AI has specific characteristics that traditional data infrastructure was never designed to provide: data aligned to specific AI use cases, automated quality gates, asset-level governance, live metadata management, and outputs that are accessible to AI agents in the right format at the right time.
Analytics systems need to produce accurate reports. AI systems need data that is accurate, contextually appropriate, and retrievable in milliseconds at a granularity that traditional BI systems were never optimised for. These are different requirements, and they need different infrastructure.
The five data challenges killing enterprise AI projects
These five problems account for the vast majority of data-related AI failures. Each one is recognisable, each one is fixable but only if it is addressed before model development begins, not after.
Concerned your data foundation is not ready for AI at scale?
GenAI Protos offers AI data engineering as a core service assessing your data environment and building the foundation your AI systems need.
Explore AI Data Engineering Services → genaiprotos.com/our-services/ai-data-engineering-services
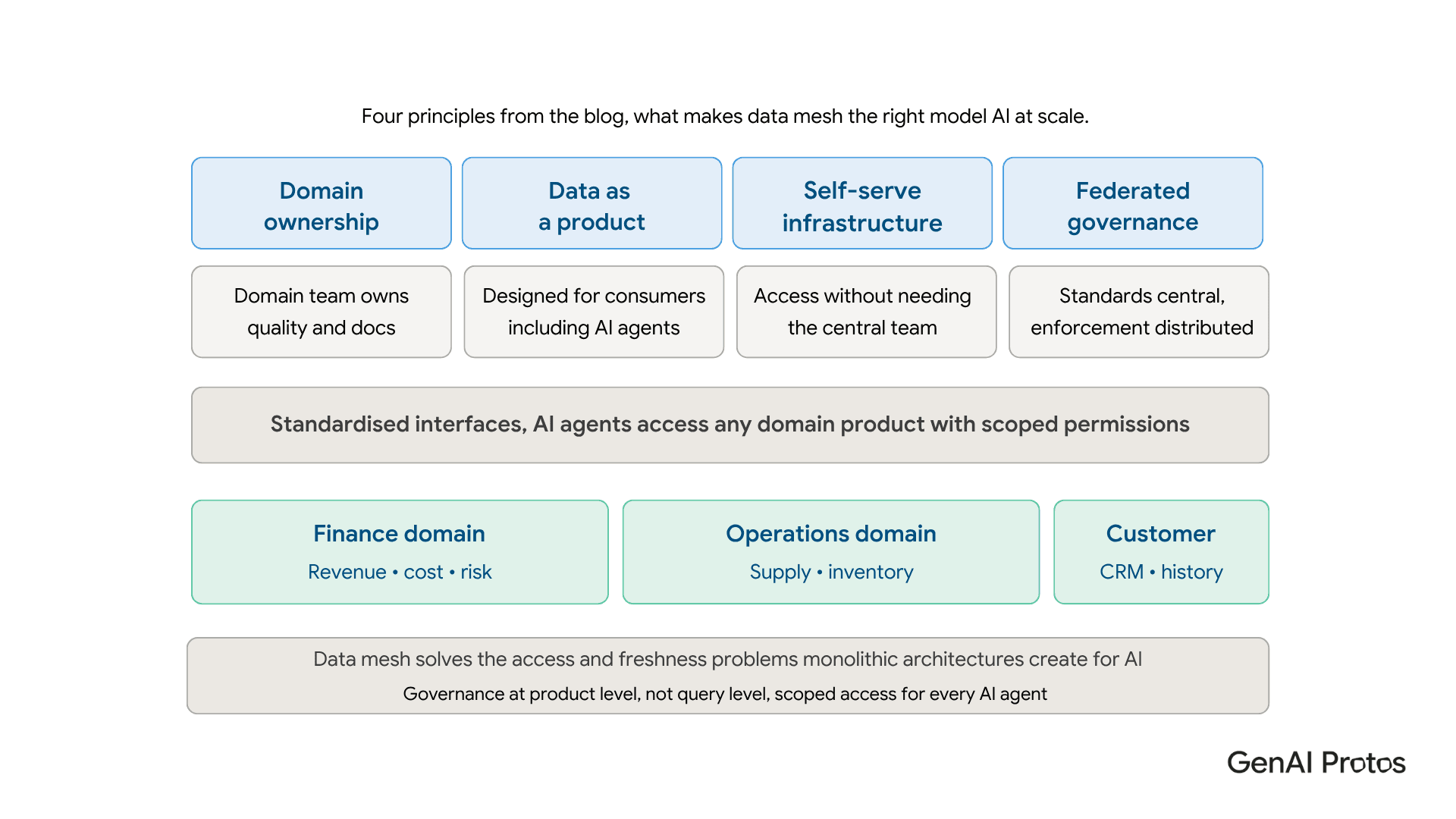
Data mesh architecture: the modern approach for AI workloads
For organisations operating at enterprise scale, data mesh architecture has emerged as the most effective way to build a data foundation that can genuinely support AI. The central idea is straightforward: rather than centralising all data into a monolithic warehouse governed by a central team, data mesh distributes ownership to the domain teams that understand their data best.
Each domain treats its data as a product designed for consumption, with clear interfaces, quality standards, and access controls. AI agents can be granted scoped access to specific data products, with governance applied at the product level rather than at the point of the individual query. This solves two problems that monolithic architectures consistently struggle with for AI workloads: access and freshness.
The four principles are domain ownership, data as a product, self-serve infrastructure, and federated governance. Standards are set centrally; enforcement is distributed. The central data team stops being the bottleneck for every data request.
Data governance for AI: it is different from what you already have
Most organisations have some form of data governance. Almost none of it was designed for AI.
Traditional data governance was built around regulatory compliance ensuring data was handled correctly for reporting and audit purposes. AI workloads introduce governance requirements that compliance-focused frameworks were not designed to address: agent access controls, output accountability, model data provenance, drift detection, and bias monitoring.
These requirements must be designed into the system architecture from the start. Retrofitting governance after an AI system is live is rarely effective, and the cost of a compliance failure or a consequential AI error after launch is significantly higher than the cost of building governance in from day one.
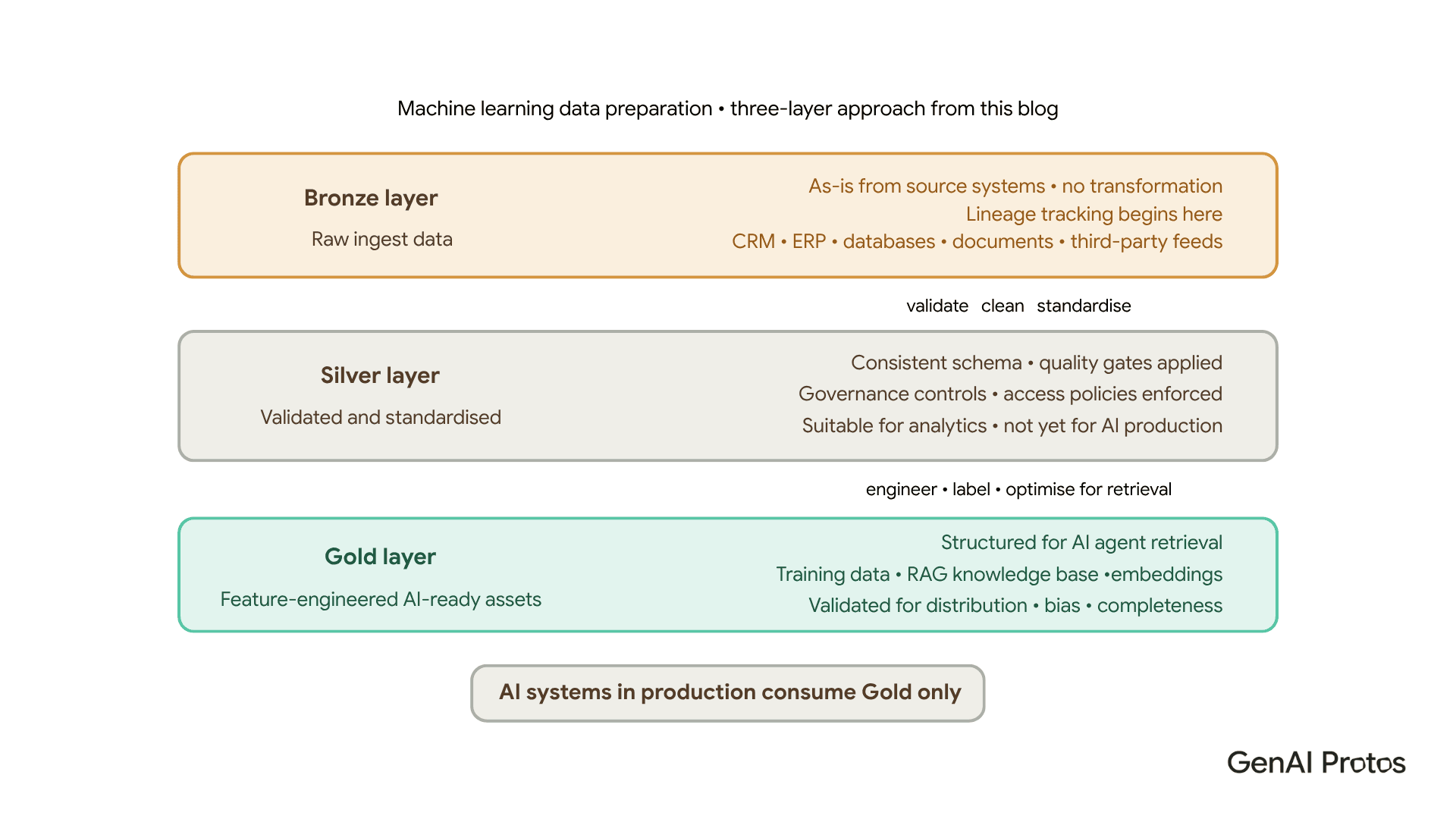
Machine learning data preparation: the step most teams rush
Machine learning data preparation is where the quality of the data foundation becomes immediately visible. Models are sensitive to the quality, distribution, and structure of their training and retrieval data in ways that are genuinely difficult to predict in advance.
The standard approach that works uses three layers. Raw ingested data enters the Bronze layer as-is from source systems no transformation, full fidelity, lineage tracking begins here. Validated and standardised data moves to the Silver layer, where quality gates are applied and governance controls enforced. Feature-engineered, AI-ready assets live in the Gold layer structured for retrieval, validated for distribution and bias, optimised for the specific AI use cases that will consume them.
Only Gold-layer data is consumed by AI systems in production. That rule is not optional it is what keeps production systems reliable over time.
A practical data readiness checklist
Before committing significant budget to AI model development, run through this checklist. If more than three items are unanswered or incomplete, the project carries meaningful data risk that should be resolved first.
- All relevant data sources identified and mapped
- Data ownership assigned at the domain and asset level
- Data quality baseline assessed against AI use case requirements
- Pipeline infrastructure supports the required ingestion frequency
- Governance policy covers agent access, output accountability, and audit logging
- Bronze-Silver-Gold layered architecture in place
- Training and retrieval data validated for distribution and bias
- Monitoring in place to detect quality degradation and distribution drift
Data foundation is not overhead. It is the multiplier that determines what return your AI investment actually delivers. The organisations that consistently get strong results from AI are, without exception, the ones that built the data layer properly before they built the models.
Is Your Data Ready for AI at Scale?
GenAI Protos assesses your current data environment, identifies the gaps, and builds the foundation your AI programme needs starting in sprint one. Book a free consultation.
Book a meeting → genaiprotos.com/book-a-meeting
