The agent passed the demo.
It failed production by week two.
Not because of the model. Because no one built the memory layer.
A support agent handles fifteen conversations before lunch. By the afternoon, it has forgotten every one of them. The next user re-explains the same account history the previous user already gave. That is not a model failure. That is what happens when an agentic AI system treats the context window as its only form of memory.
This guide covers what agent memory actually requires, how the three memory layers differ in purpose and implementation, and the mistakes that cause production agents to behave as if every session is their first.
What Agent Memory Is (and What It Is Not)
Agent memory is the mechanism by which an agent retrieves relevant context before each session begins. It is not the model's context window. The context window is what the model can see in a single call. Memory is the infrastructure that decides what gets placed there, and what does not.
The distinction matters in production. Context windows are expensive, have hard size limits, and reset on every API call. An agent that relies on the context window alone loses everything when the session closes. Every new session starts from zero, regardless of how many prior interactions the agent has had.
Memory is the architecture that makes context persistent. Without it, even a well-configured model behaves as if it has never met this user before. This is the infrastructure gap that agentic AI deployments most consistently underestimate.
Three Memory Layers Every Agentic AI System Needs
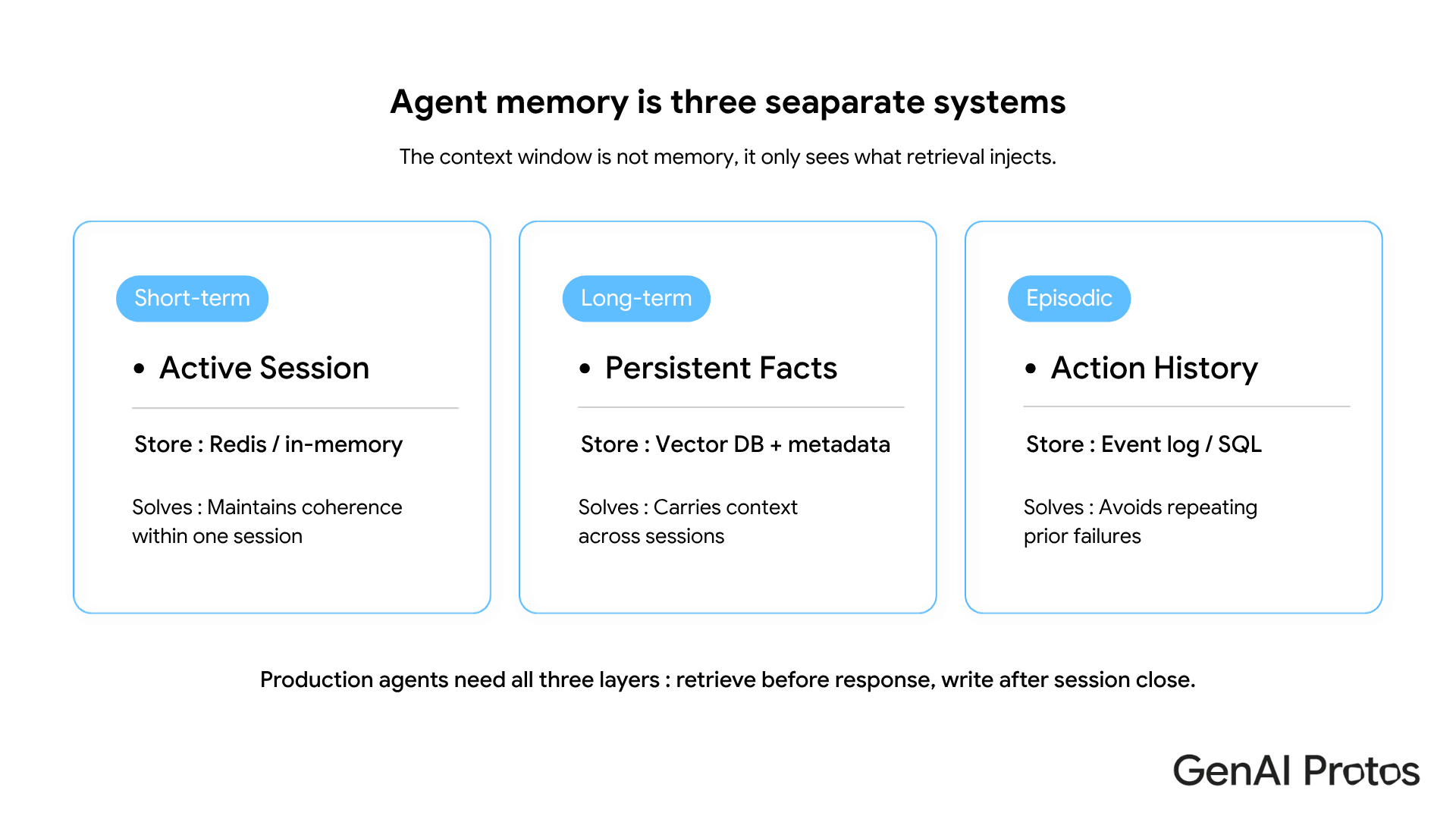
Short-Term Memory: The Working Session
Short-term memory holds the active conversation state. It is the buffer of recent exchanges the agent uses to maintain coherence within a single session. Implementation is an in-memory store or Redis cache, keyed to the session ID, with a TTL of 30 to 60 minutes.
The failure mode is treating this as the only memory layer. Sessions expire, context evaporates, and the agent starts fresh. For enterprise AI deployments handling repeat users or multi-session workflows, that is a product failure, not a configuration issue.
Long-Term Memory: What Persists Across Sessions
Long-term memory stores facts, preferences, and history that must survive session expiry. For an enterprise agent, this includes user role, prior decisions, escalation history, and domain-specific context for that account.
Implementation requires a vector database with a retrieval layer that pulls the top-k relevant facts into the context window at session start. The write pipeline matters as much as the read: every meaningful session event should be summarised and written back before the session closes. Skipping the write step is the most common reason production agents learn nothing from prior interactions.
Episodic Memory: What the Agent Tried Before
Episodic memory records the sequence of past actions and their outcomes. It gives the agent a structured record of what it attempted, what succeeded, and what was escalated. Implementation is a structured event log: task ID, action taken, outcome, and timestamp.
This layer prevents the most visible production failure: an agent that repeats the same mistake on the same task type because it has no record of what happened last time.
| Memory Layer | Store | Scope | Purpose | Implementation |
|---|---|---|---|---|
| Short-term | In-memory / Redis | Single session | Session coherence | Redis, TTL 30-60 min |
| Long-term | Vector database | Cross-session | Facts, preferences, history | Pinecone, Weaviate, pgvector |
| Episodic | Event log / SQL | Persistent | Past actions, outcomes | PostgreSQL, structured log |
Production Memory Architecture for Multi-Agent Systems
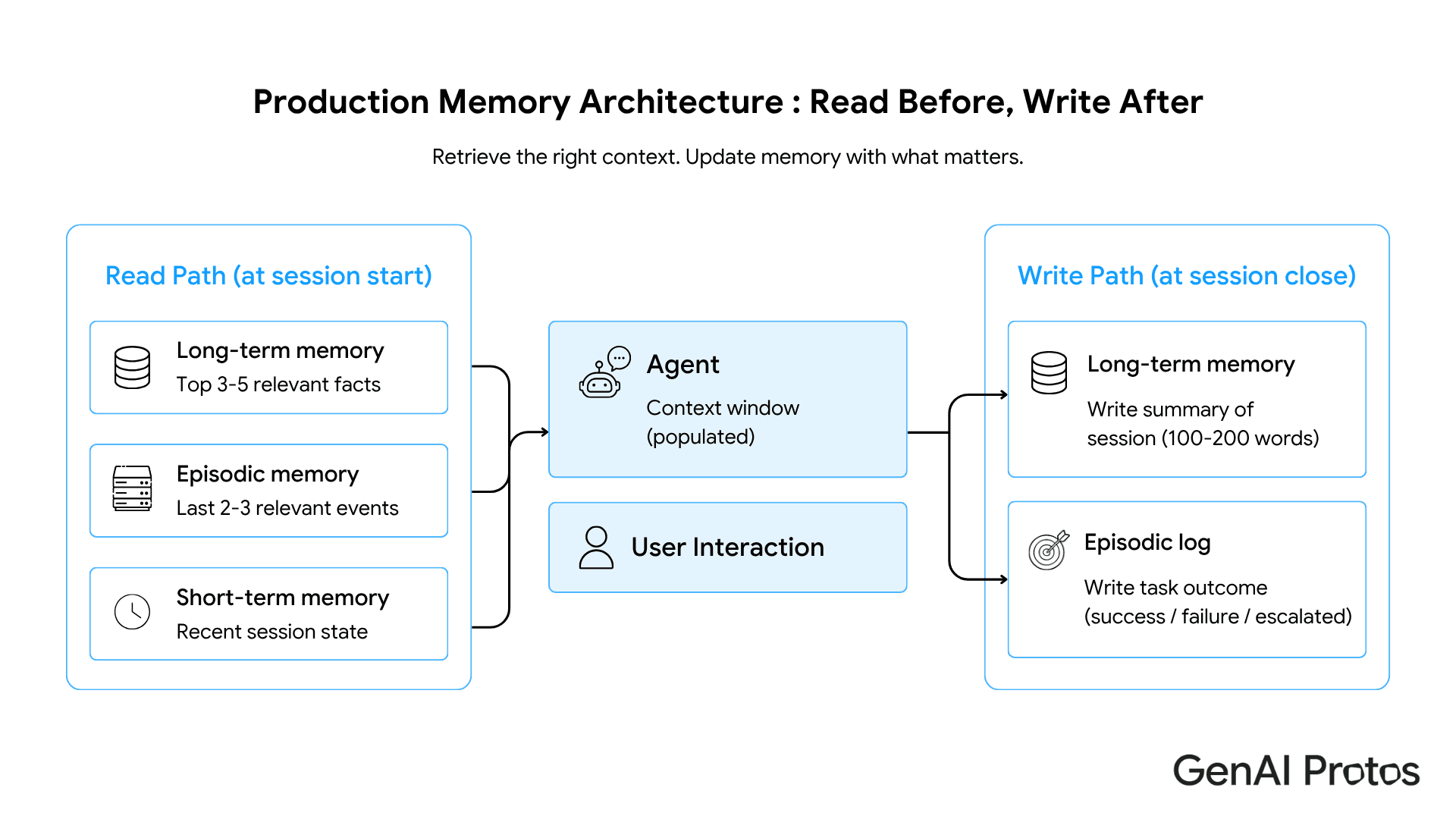
Multi-agent systems introduce a memory challenge that single-agent builds do not face: context must be shared across agents without being duplicated, and handoffs must preserve state without losing task-specific detail.
The pattern that holds at production scale uses a shared long-term memory store with agent-scoped retrieval. Each agent queries the store for facts relevant to its role. Short-term memory stays local to each agent. Episodic memory is written to a shared log, keyed by task ID, so any agent in the pipeline can access prior actions on the same task.
The read and write discipline is what separates agentic AI pipelines that hold in production from those that degrade over time. Retrieve at session start. Write at session close. Both steps are required on every interaction, not only on the interactions that feel significant.
Multi-agent systems that skip write-back at session close produce pipelines that degrade progressively. Each agent in the chain knows less about prior context than it should. Errors from incomplete context compound across handoffs. The failure appears as general unreliability and takes longer to diagnose than the fix would have taken to build.
3 Enterprise AI Memory Mistakes That Break Production Agents
Treating the context window as persistent memory. Teams that understand the distinction still make this mistake: they budget for a larger context window instead of building a memory layer. The result is an agent that costs more per session, hits a hard ceiling on history length, and still loses everything when the session closes. The fix is a separate memory layer, not a bigger context window.
No write discipline on session close. The write steps happen after the user leaves, so they feel low-priority. They are not. An enterprise AI agent that does not write back on session close learns nothing from its interactions. Every session restarts from whatever state was written last, which in most builds means near-zero context. This is the single most common cause of the dumb agent complaint in production.
One collection for everything. Long-term facts and episodic events have different retrieval patterns. Mixing them in a single vector database collection degrades retrieval precision. Long-term memory needs dense embeddings for semantic fact retrieval. Episodic memory needs structured metadata filters for outcome-based lookup. Keep them in separate collections.
An agentic AI system that repeats these mistakes does not fail all at once. It degrades gradually: slightly worse context on each session, slightly more user frustration on each repeat visit, until the product team starts asking why users stopped trusting the agent.
How to Choose a Vector Database for Agent Long-Term Memory
Most agentic AI teams over-engineer the store selection and under-engineer the write pipeline that feeds it. The store is the easy part. Deciding what to write, when to write it, and how to expire stale facts is where production memory architecture actually lives.
The store selection itself is straightforward: managed service or self-hosted. Pinecone and Weaviate offer strong semantic search performance with predictable latency at scale. pgvector works well for teams already on PostgreSQL who want to avoid a new infrastructure dependency.
Vector Database Options: At a Glance
| Store | Best Use Case | Strength | Limitation |
|---|---|---|---|
| Pinecone | Managed, fast time-to-production | Consistent low-latency retrieval at scale | Vendor lock-in, higher cost at volume |
| Weaviate | Hybrid search with metadata filters | Flexible schema, supports dense and sparse | More ops overhead than Pinecone |
| pgvector | Teams already running PostgreSQL | No new infrastructure dependency | Slower at very high vector volumes |
Performance across all three is sufficient for most enterprise AI agent workloads at moderate query volumes. The structural decision matters more than the vendor choice: keep long-term facts and episodic events in separate collections with separate embedding strategies. Dense embeddings for semantic fact retrieval, structured metadata filters for episodic lookup.
Mixing them is the most common vector database configuration mistake in agent production builds, and the one that degrades retrieval precision in ways that are slow to diagnose. When retrieval returns stale or irrelevant facts, the agent responds with outdated context. The model is not wrong. The memory layer is.
How to Evaluate Agent Memory Before Production
Shipping an agent with untested memory produces the same failure as shipping an agent with no memory. The failure only becomes visible once real users hit it. Six metrics indicate whether a memory layer is performing before it handles real production volume.
For multi-agent systems, run this evaluation at the individual agent level as well as the pipeline level. Memory failures at individual agent boundaries compound silently before surfacing as pipeline-level failures.
Agent Memory Evaluation Metrics
| Metric | What it Measures | Threshold | What It Indicates |
|---|---|---|---|
| Retrieval Precision | % of retrieved facts relevant to the session | Below 70% | Embedding strategy or chunking approach needs revision |
| Write-back Success Rate | % of sessions that write to long-term memory at close | Below 95% | Write pipeline has reliability gaps |
| Stale Memory Rate | % of retrieved facts that are outdated | Above 10% | Record update logic is missing or incorrect |
| Repeated Failure Rate | % of sessions where the agent repeats a previously-failed action | Any non-zero | Episodic memory is not being read at session start |
| Re-explanation Rate | % of sessions where users re-explain context already given | Above 5% | Long-term memory retrieval is not working |
| Human Escalation Rate | % of escalations caused by context gaps vs. model failure | Benchmark per product | Isolates memory failures from model failures |
Build a test set from your actual agent corpus before deploying any agentic AI memory layer. Retrieval quality failures are invisible until they produce visible agent failures, and by that point the damage to user trust is already done.
Agent memory is the infrastructure problem that enterprise teams consistently underestimate. The model gets evaluated carefully before launch. The memory architecture gets designed the week before go-live. Every agentic AI system that earns user trust earns it through consistent retrieval, across sessions, users, and task sequences. Each of the three layers is a separate engineering decision. All three are required.



