Why Standard RAG Is Breaking Down in Enterprise Production
When enterprises first deployed retrieval-augmented generation, the use case was clear: take a question, retrieve the most relevant chunks from a vector database, inject them into a prompt, and generate an answer. For simple, document-level Q&A, that pipeline works adequately.
The problem is that enterprise workloads are not simple.
A compliance team needs to cross-reference six regulatory filings, compare them against a live API, and flag discrepancies not in sequence, but simultaneously. A procurement system needs to match vendor submissions, validate against approved supplier lists, check compliance flags, and trigger an approval workflow in one connected operation. A research agent needs to pull from structured databases, unstructured PDFs, and external knowledge sources, evaluate confidence at each step, and retry when the context is insufficient.
Standard RAG fails on all of these. It retrieves once, generates once, and stops. There is no evaluation loop. There is no retry logic. There is no awareness that the first retrieval pass may have missed the critical context sitting two hops deeper in the knowledge graph.
The data confirms it. McKinsey's 2026 Enterprise AI Adoption Report found that 58% of enterprise AI teams that deployed standard RAG in 2024identified multi-step reasoning over heterogeneous data sources as their top limitation within six months. That is not a model problem. It is an architecture problem.
Agentic RAG architecture is the structural response to that failure mode. And in 2026, it has moved from research concept to production deployment across regulated industries, financial services, and enterprise automation at scale.
What Is Agentic RAG Architecture?
Agentic RAG architecture is an advanced evolution of standard retrieval-augmented generation that places an autonomous AI agent at the centre of the retrieval and generation pipeline. Instead of following a fixed retrieve-then-generate sequence, the agent plans a retrieval strategy, dynamically selects tools, evaluates the quality and completeness of retrieved context, and iterates until it has sufficient grounding to produce a reliable answer.
In simple terms: standard RAG is a pipeline. Agentic RAG is a reasoning loop.
The key conceptual shift is that retrieval becomes a tool the agent uses not a predetermined step in a fixed sequence. The agent decides what to retrieve, when to retrieve more, and when the context is sufficient to generate a response with confidence. This transforms the system from a passive information fetcher into an active decision-maker.
Agenticretrieval augmented generation is not a single architecture. It is a class ofarchitectures each one built around the same core principle of autonomous reasoning over retrieval differing in how the orchestrator plans, how tools are selected, and how the system evaluates its own outputs before responding.
How Agentic RAG Architecture Works: The 4-Layer System
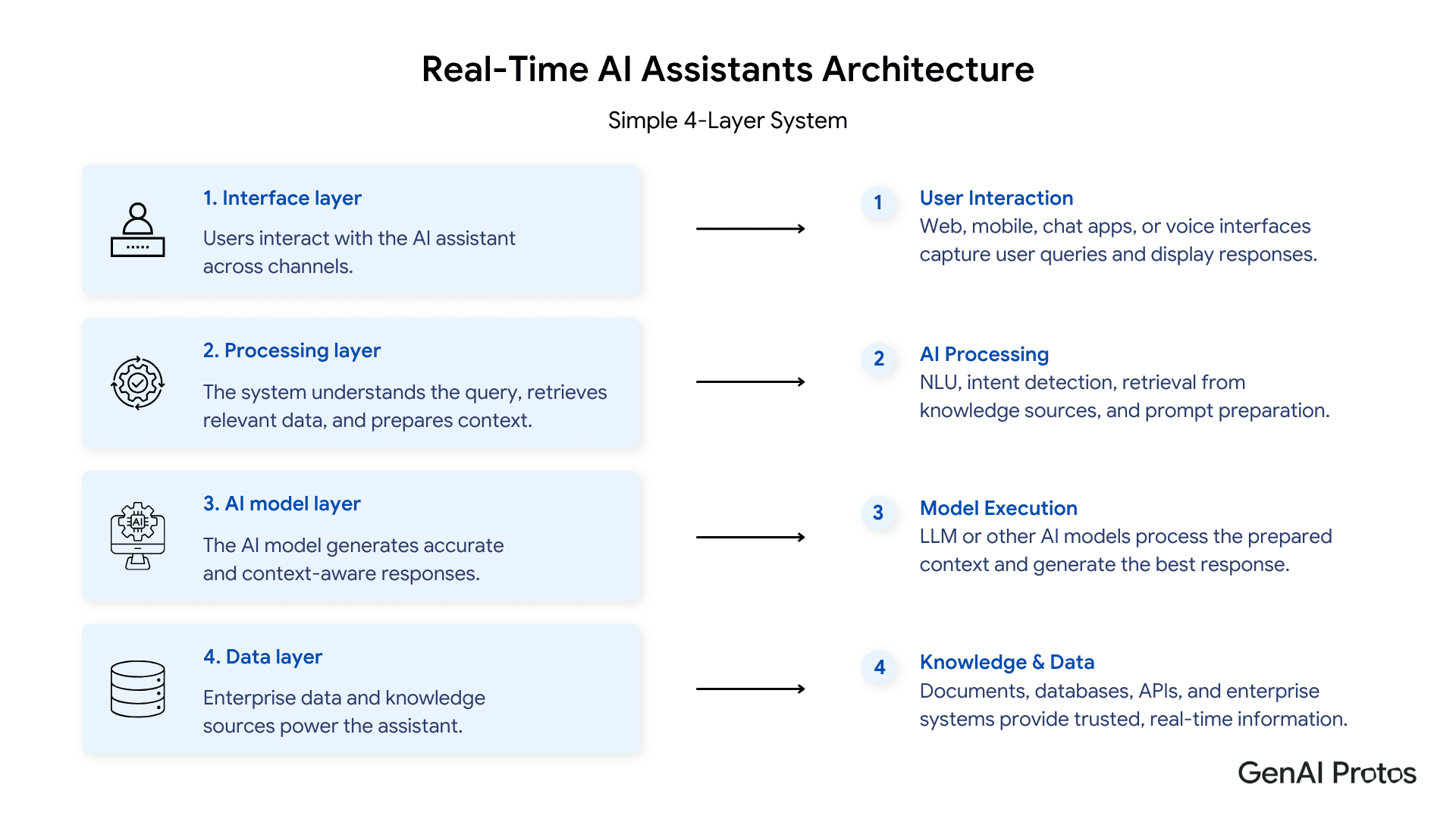
Agentic RAG introduces an autonomous reasoning and evaluation layer that continuously validates retrieved context before generating a final response.
Every production-grade agentic RAG architecture is built across four interconnected layers. Understanding how these layers work and how they interact is the foundation for designing systems that hold up in enterprise production.
Layer 1: The Orchestrator Agent
The orchestrator sits at the top of every agentic RAG system. It receives the user's query or goal, interprets intent, and builds a retrieval plan before a single document is fetched.
The orchestrator is responsible for three things: decomposing complex queries into retrievable sub-tasks, routing each sub-task to the right tool or retrieval strategy, and deciding at each step whether the accumulated context is sufficient to proceed or whether another retrieval pass is required.
In 2026, the enterprise standard orchestrator models are Claude 3.5 Sonnet for its strong instruction-following and self-assessment capabilities, and GPT-4o for teams already operating within Azure infrastructure. The choice of orchestrator model directly determines the quality of the planning and self-evaluation loop and is one of the four design decisions that separates production success from a 90-day failure.
Layer 2: The Retrieval Tool Suite
Where standard RAG uses a single retrieval mechanism most commonly cosine similarity over a vector database agentic RAG equips the agent with a full suite of retrieval tools it can invoke contextually.
A typical enterprise retrieval tool suite includes:
- Vector search - semantic similarity retrieval over embedded document stores
- Keyword search (BM25) - exact-match retrieval for technical terms, product names, and regulatory codes where semantic search underperforms
- Graph traversal - relationship-based retrieval for connected data (contracts, org charts, compliance frameworks)
- API calls - live data retrieval from external systems, CRMs, financial databases, or regulatory feeds
- Structured query tools - SQL or NoSQL lookups against enterprise databases
The orchestrator selects the right tool for each sub-task or combines multiple tools in sequence rather than defaulting to a single retrieval mechanism regardless of what the query actually requires. This is the architectural reason agentic RAG produces more accurate answers on complex enterprise queries than any single-strategy retrieval pipeline can.
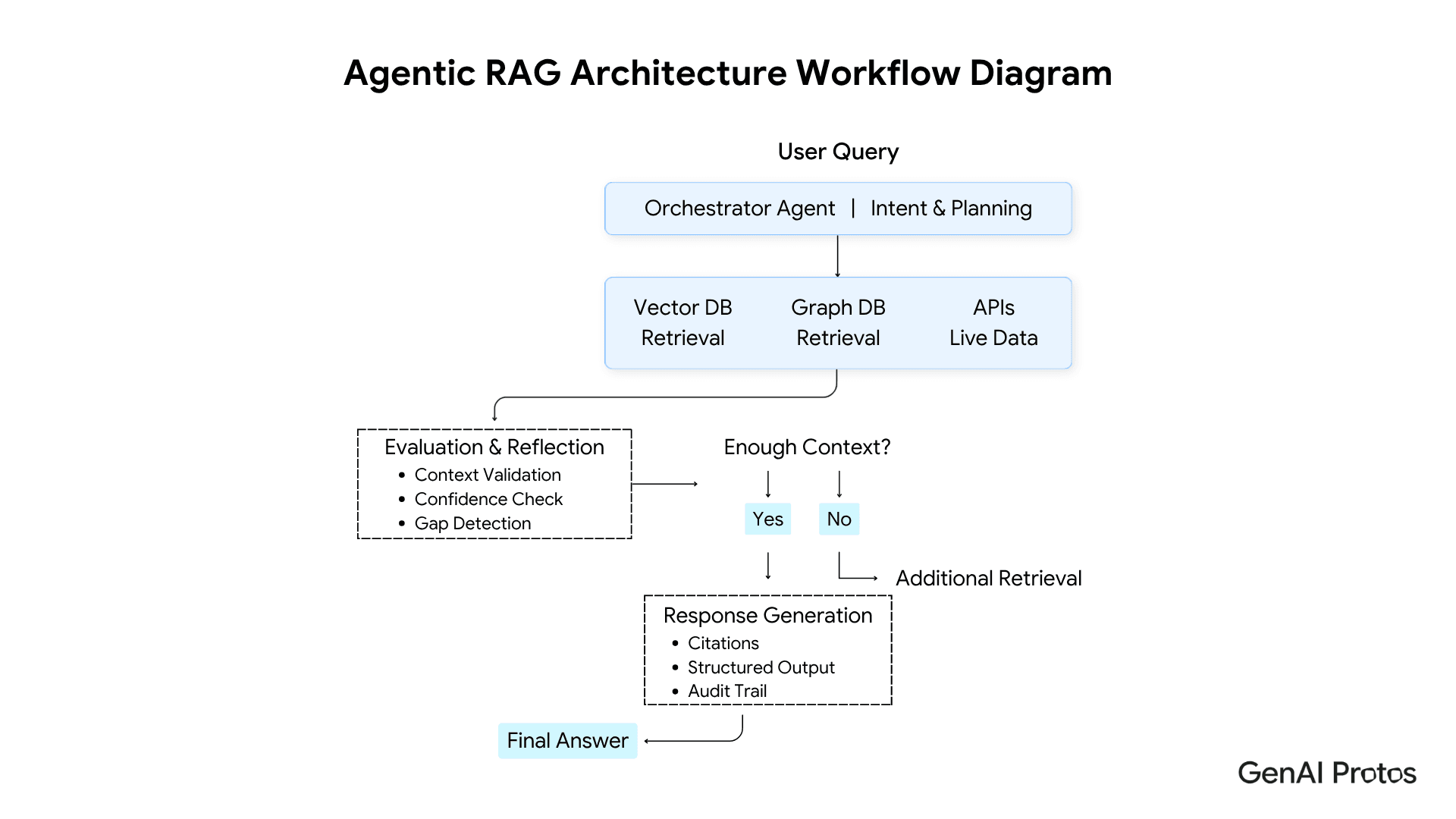
Layer 3: The Evaluation and Reflection Loop
This layer is what makes agentic RAG architecture fundamentally different from every pipeline-based approach that preceded it.
After each retrieval pass, the agent evaluates three things: Does the retrieved context actually answer the sub-task? Is the retrieved information sufficiently recent and authoritative? Are there gaps that a follow-up retrieval could address?
If the answer to any of these is no, the agent iterates. It reformulates the query, selects a different retrieval tool, or expands the scope of the search before proceeding. This self-evaluation capability is the direct fix for the most common failure mode of standard RAG retrieving plausible but incomplete context and generating a confident but wrong answer.
For enterprise deployments in regulated industries, this evaluation layer also serves a governance function. Audit logging at each retrieval step, confidence scoring before generation, and human-in-the-loop checkpoints at defined decision thresholds are all implemented within this layer.
Layer 4: Generation and Structured Output
Only after the orchestrator is satisfied that the retrieved context is sufficient does the system proceed to generation. The LLM generates an answer grounded exclusively in the verified, retrieved context not in parametric memory, not in training data, not in assumptions.
In production enterprise systems, this layer also handles output formatting: structured JSON for downstream systems, cited responses with source references for compliance requirements, or executive summaries with confidence scores for decision-support workflows.
The result is a response that is not only accurate it is auditable. Every claim traces back to a verified source retrieved in that specific session. For regulated industries operating under GDPR, HIPAA, the EU AI Act, or internal governance frameworks, this traceability is not optional. It is the baseline requirement.
Agentic RAG vs Standard RAG: The Architecture Comparison
Understanding the difference between agentic RAG vs standard RAG at the architecture level is essential before making any deployment decision.
| Dimension | Standard RAG | Agentic RAG Architecture |
|---|---|---|
| Retrieval strategy | Single-pass, fixed pipeline | Multi-pass, dynamically planned |
| Query handling | One retrieval per query | Sub-task decomposition + iterative retrieval |
| Tool access | One retrieval mechanism | Full tool suite (vector, BM25, graph, APIs) |
| Self-evaluation | None | Evaluates context sufficiency at each step |
| Multi-hop reasoning | Not supported | Core capability |
| Latency | Low (single pass) | Higher (multiple passes) |
| Cost | Lower | Higher per query |
| Best for | Simple Q&A, single knowledge source | Complex reasoning, multi-system enterprise workflows |
| Governance support | Limited | Full audit trail, human-in-the-loop checkpoints |
The critical takeaway from this comparison: agentic RAG architecture is not universally better than standard RAG. It is better for a specific class of problem complex, multi-step enterprise queries over heterogeneous data sources where standard retrieval fails. For simple, high-volume Q&A over a single, well-structured knowledge base, standard RAG with hybrid retrieval and a reranker is often the right answer at significantly lower cost and latency.
The architecture decision should follow the problem not the other way around.
5 Agentic RAG Architecture Patterns for Enterprise Production
Agentic RAG is not one system. It is a family of patterns, each designed for a different enterprise use case and complexity level. These five patterns cover the majority of production enterprise deployments in 2026.
Pattern 1: Router RAG
Complexity: Low | Best for: Multi-source knowledge bases, mixed query types
The router pattern places a lightweight classification agent before the retrieval layer. When a query arrives, the router determines which retrieval strategy vector search, keyword search, structured query, or external API is the best fit for that specific question, then routes accordingly.
This is the lowest-cost entry point into agentic RAG architecture and the right starting pattern for enterprises with multiple data sources that currently require manual routing or produce inconsistent results from a single retrieval strategy.
Pattern 2: ReAct RAG (Reason + Act)
Complexity: Medium | Best for: Research tasks, knowledge-intensive workflows, document analysis
ReAct interleaves reasoning and retrieval in an explicit loop. The agent reasons about what it needs, retrieves context, reasons about whether that context is sufficient, retrieves more if needed, and continues until it can answer with confidence. Each reasoning and retrieval step is logged making this pattern ideal for compliance-sensitive workflows where the retrieval chain must be auditable.
ReAct RAG is currently the most widely deployed agentic RAG pattern in enterprise production, used in legal document review, regulatory compliance querying, and clinical documentation workflows.
Pattern 3: Plan-and-Execute RAG
Complexity: High | Best for: Multi-step enterprise research, procurement analysis, financial reporting
The planner agent receives a complex goal and generates a full retrieval plan before any execution begins. The plan decomposes the goal into discrete sub-tasks, assigns retrieval strategies to each, and defines the expected output structure. A separate executor agent then carries out the plan in parallel where possible, assembling a structured response from the aggregated context.
This pattern produces the highest-quality outputs for complex, multi-step queries but at higher latency and cost. It is the right choice for workflows where answer quality is the primary constraint and throughput is secondary.
Pattern 4: Multi-Agent Retrieval RAG
Complexity: High | Best for: Enterprise-scale knowledge bases with siloed data across business units
Multiple specialized retrieval agents each assigned to a specific data domain, language, or system operate in parallel and report back to a synthesis agent that assembles the final response. This pattern is particularly effective in enterprises with heterogeneous knowledge silos: separate vector stores for legal, finance, and operations, different knowledge bases across geographies, or mixed data types requiring specialist retrieval strategies per domain.
GenAI Protos deploys multi-agent retrieval RAG in enterprise environments where no single retrieval strategy can span the full knowledge landscape enabling AI systems to access the right information from the right source for every query, regardless of where that knowledge lives.
Pattern 5: Self-RAG (Self-Reflective Retrieval)
Complexity: Medium | Best for: High-accuracy use cases, regulated industries, customer-facing AI systems
The self-RAG pattern introduces an explicit self-assessment step where the agent critiques its own retrieved context and generated output before returning a response. If the self-critique identifies gaps, factual uncertainty, or insufficient grounding, the system triggers an additional retrieval pass. If the response meets the defined quality threshold, it proceeds to output.
Self-RAG consistently produces the highest factual accuracy of any agentic RAG architecture pattern at the cost of higher latency per response. For healthcare documentation, legal clause extraction, and financial compliance workflows where a confident wrong answer carries real operational risk, that latency trade-off is consistently worth it.
When to Use Agentic RAG vs Standard RAG: The Decision Framework
This is the question most enterprise teams get wrong. The decision is not "Is agentic RAG better?" The decision is "Does this specific use case require agentic RAG, or will standard RAG deliver adequate results at lower cost and complexity?"
Deploy agentic RAG architecture when:
- The query requires information from more than one system, database, or knowledge source
- The answer depends on multi-hop reasoning where fact B only becomes relevant after finding fact A
- The workflow has compliance or auditability requirements that demand a retrievable reasoning chain
- Answer quality is the primary constraint and latency is acceptable (above 3–5 seconds)
- The use case involves complex document analysis, regulatory cross-referencing, or structured research tasks
- Your enterprise data is distributed across siloed systems with different retrieval characteristics
Stay with standard RAG when:
- Queries are primarily single-hop and document-level (one question, one document section)
- Throughput and latency are the primary constraints (customer-facing chat, real-time support)
- Your knowledge base is a single, well-structured vector store with clean, semantically consistent documents
- The team does not yet have ML engineers with experience in agent orchestration frameworks
- You are in the early stages of AI deployment and need a working system in weeks, not months
The most effective production architecture in 2026 is a hybrid:
standard RAG with BM25 hybrid retrieval and a cross-encoder reranker handles the 70–80% of queries that are straightforward. Agentic RAG handles the 20–30% of queries that require multi-step reasoning. This split delivers the performance of agentic retrieval augmented generation where it matters without paying its cost and latency penalty on queries that do not need it.
Enterprise Use Cases Where Agentic RAG Delivers Real ROI in 2026
Agentic RAG use cases have moved well beyond experimental pilots. These are production deployments with measurable outcomes.
Regulatory Compliance Intelligence
A Tier-1 financial institution deployed an agentic RAG architecture to handle compliance queries that previously required senior analysts to manually cross-reference regulatory databases, internal policy documents, and historical precedents. The multi-agent retrieval system now answers complex regulatory questions in minutes with clause-level citations and a full audit trail reducing the average compliance lookup time from 3–4 hours to under 12 minutes.
Clinical Documentation Review
Healthcare organizations using agentic RAG for clinical documentation are processing structured medical queries that span patient records, clinical guidelines, and drug interaction databases in a single workflow. The self-reflective retrieval pattern ensures every output is grounded in verified clinical sources a non-negotiable requirement in HIPAA-regulated environments where the standard RAG hallucination rate is an operational liability.
Enterprise Knowledge Management
Large enterprises with knowledge distributed across SharePoint, Confluence, internal wikis, email archives, and proprietary databases are deploying multi-agent retrieval RAG to surface answers that no single-source retrieval system could produce. Research that previously took analysts hours now surfaces in structured, source-cited outputs in under two minutes.
Legal Contract Analysis
Law departments using Plan-and-Execute RAG are processing contract portfolios for risk flags, non-standard clause identification, and cross-document consistency checks at 3–4x the throughput achievable with human-only review while maintaining full traceability of every retrieval decision for compliance purposes.
Example: Enterprise Compliance Agentic RAG Workflow
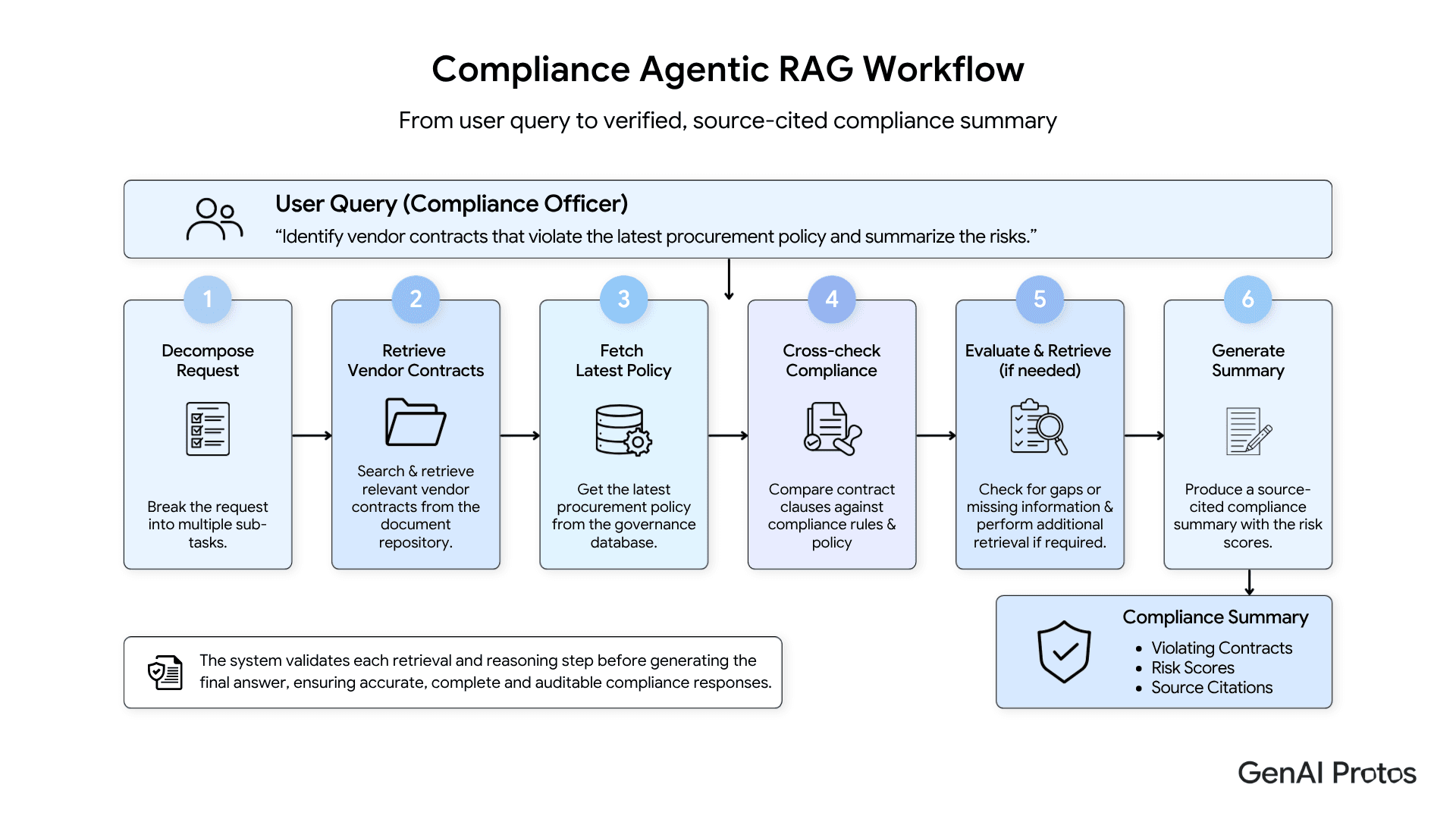
A compliance officer asks:
“Identify vendor contracts that violate the latest procurement policy and summarize the risks.”
The Agentic RAG system performs the following steps:
- Decomposes the request into multiple sub-tasks.
- Retrieves vendor contracts from the document repository.
- Fetches the latest procurement policy from the governance database.
- Cross-checks clauses against compliance rules.
- Evaluates missing information and performs additional retrieval if required.
- Generates a source-cited compliance summary with risk scores.
Unlike standard RAG, the system validates each retrieval step before producing a response, reducing the risk of incomplete or unsupported recommendations.
What Does Agentic RAG Implementation Actually Require?
Understanding the agentic RAG architecture is one thing. Building it in production is another. Here is what enterprise teams consistently underestimate when they start implementation.
Orchestration frameworkselection. The two leading open-source options in 2026 are LangGraph best for complex, stateful workflows with conditional branching and fine-grained control over the reasoning loop and LlamaIndex Workflows, which provides a higher-level abstraction with strong document-processing integrations. GenAI Protos also works with Agno, a high-performance autonomous agent framework built specifically for production-grade multi-agent systems with lower latency overhead than LangGraph for certain workload patterns.
Evaluation infrastructure. An agentic RAG system without a robust evaluation stack is flying blind in production. You need faithfulness scoring (does the answer reflect the retrieved context?), context precision (was the retrieved context actually relevant?), and answer relevance (does the output address the original query?). Tools like LangSmith and Ragas provide the observability layer that makes this measurable and debuggable at scale.
Data quality and chunking strategy. The most common cause of poor agentic RAG performance is not the agent architecture it is the retrieval layer underneath it. Semantic chunking, metadata enrichment, and hybrid indexing are prerequisites for any multi-pass retrieval system to function reliably. Garbage in at the data layer means garbage out regardless of how sophisticated the orchestration layer is.
Governance and cost controls. Agentic systems that iterate across multiple retrieval passes and tool calls accumulate cost at every step. Production deployments need explicit token budget controls, retrieval pass limits, and human-in-the-loop checkpoints at defined cost or uncertainty thresholds. Building governance in from the start is significantly less expensive than retrofitting it after the system is live.
| Framework | Best For | Strength |
|---|---|---|
| LangGraph | Complex enterprise workflows | State management and conditional execution |
| Agno | Production multi-agent systems | High performance and lower orchestration overhead |
| LlamaIndex Workflows | Knowledge-intensive applications | Strong document processing and retrieval integrations |
| CrewAI | Collaborative agent systems | Multi-role agent coordination |
| AutoGen | Conversational multi-agent workflows | Agent-to-agent communication and automation |
How GenAI Protos Builds Agentic RAG Systems for Enterprise
At GenAI Protos, agentic RAG architecture is not a framework we configure it is a system we engineer from the retrieval layer up, aligned to the specific data topology, compliance requirements, and performance constraints of each enterprise environment.
Our work spans the full implementation stack: data architecture and indexing strategy, orchestration framework selection, evaluation infrastructure, governance design, and production deployment. We bring experience across LangGraph, LlamaIndex, and Agno-based multi-agent retrieval systems, with production deployments in financial services, healthcare, and enterprise knowledge management.
The result is an agentic RAG system calibrated for your data, your compliance requirements, and your operational constraints not a generic template adapted to a problem it was not designed for.
If your current RAG system is producing inconsistent results on complex queries, struggling with multi-system data access, or failing to meet the auditability requirements of a regulated environment, the underlying architecture not the model is almost certainly the constraint.
Conclusion: The Architecture Defines What Your AI Can Know
Retrieval-augmented generation is no longer a feature layer bolted on top of an LLM. In 2026, it is enterprise AI infrastructure and the architecture of that retrieval layer determines what your AI system can reliably know, how it reasons under complexity, and whether its outputs are trustworthy enough to operate in production at scale.
Agentic RAG architecture is the right answer for enterprise workloads that have outgrown the limits of static, single-pass retrieval pipelines. It is not the right answer for every use case but for the class of problems it is designed to solve, no alternative currently delivers comparable accuracy, auditability, or adaptability.
The question for enterprise teams in 2026 is not whether to move toward agenticretrieval augmented generation . It is whether to build that capability now, while the SERP and the competitive landscape are still navigable or wait until every enterprise in your sector has already done it.
