Introduction
Every engineering org has rolled out an AI coding tool. Half rolled out three. The honest question: did any of it move cycle time, change failure rate, on-call load, time-to-merge, or retention? Most leaders answer, “we think so, but can’t prove it.” That’s a no.
AI agents for software engineering work in 2026, but only in specific shapes, at specific SDLC stages, with specific integration patterns. Outside those, they’re toys that add tool sprawl.
This guide draws the line so engineering leaders can stop running pilots and start running programs. You’ll get a stage-by-stage SDLC map, the integration layers that decide success, the four patterns that survive the pilot, and the measurement honesty required to know if your investment compounds.
Section 1: What an AI Agent for Software Engineering Actually Is in 2026
An AI agent for software engineering is not an autocomplete plugin. It’s a system that understands a real codebase, calls developer tools (git, CI, ticketing, code search, browsers), executes multi-step tasks with explicit checkpoints, and stops when uncertain. “AI coding tool” no longer means anything specific. Shape matters, not vendor.
Three shapes worth naming because their failure modes and ROI profiles differ:
Inline assistants.
Live in the editor, complete code, answer questions about the open file. Low risk, low ceiling, easy ROI. Most teams already have this.
Repository-aware agents.
Understand the whole codebase. Navigate, search, refactor, draft PRs, follow conventions. The shape most “we tried it and it was confusing” stories belong to, because the integration depth required is real.
Workflow agents in the SDLC.
Live alongside developers, not inside the editor. Triage issues, draft PR descriptions, summarize incidents, monitor flaky tests. Closer to a junior teammate than a tool.
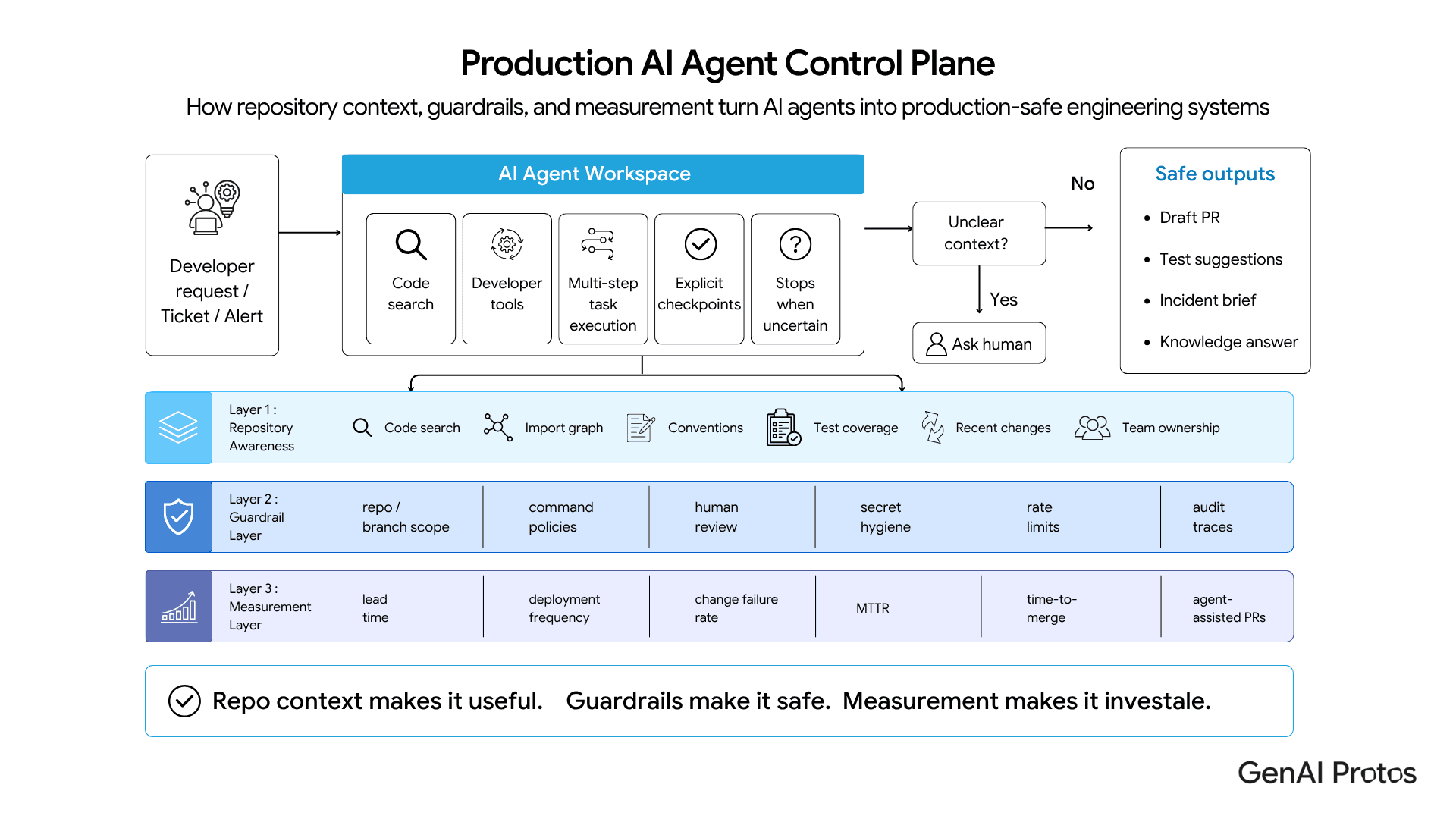
Section 2: The Three Integration Layers That Decide Whether It Works
Whether an AI agent helps your team or wastes its time comes down to three layers: repository awareness, guardrails, and impact measurement. Skip one and the rollout quietly fails.
Layer 1: Repository awareness
A repo-aware agent has indexed your code, understands your import graph, knows your conventions, and navigates dependencies. Without it, the agent writes code that compiles but doesn’t fit. With it, code that fits but may still be wrong. The gap is real.
What good looks like in 2026: structured code search across the repo, awareness of test coverage and recent changes, sandboxed runtime inspection, and team ownership awareness.
Layer 2: Guardrails
Where most rollouts under-invest. Guardrails decide what the agent can touch, what it must check before acting, and when it must stop. For agents that open PRs, run commands, or hit production, this layer is the difference between a productive teammate and a security incident waiting for its date stamp.
A working guardrail layer includes scope rules (which repos, branches, commands), action policies (when to run tests, wait for review, or stop), secret hygiene (no credentials in prompts or traces), and rate limits on agent-initiated actions.
Layer 3: Impact measurement
Developer vibes are not enough. Winning orgs pair the rollout with a small, honest measurement plan grounded in metrics they already track: lead time for changes, deployment frequency, change failure rate, MTTR, PRs touched by agents, suggestion acceptance rate, and time-to-merge for agent-assisted PRs.
Section 3: The SDLC Map: Where Agents Earn Their Keep, Stage by Stage
AI agents pay off unevenly across the SDLC. They’re strong at code generation, code review assistance, test scaffolding, incident summarization, and engineering knowledge search. They’re weak at design, architectural decisions, security review, and anything requiring real-world judgment the model cannot ground. This map is the most important artifact a VP of Engineering can keep on the wall.
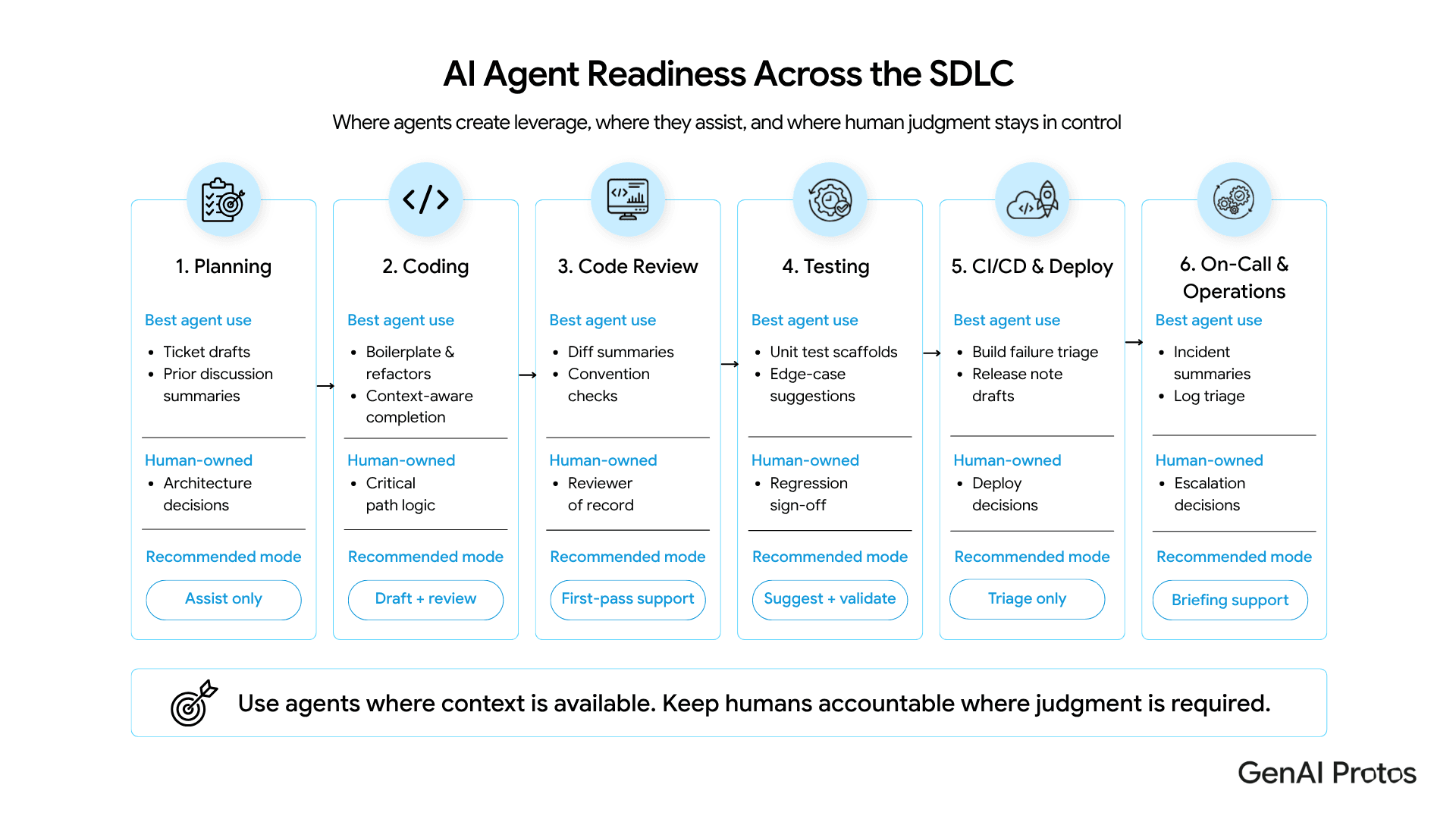
Planning and design:
Works: drafting ticket descriptions from short notes, summarizing prior discussions, suggesting test cases from acceptance criteria. Doesn’t yet: architectural calls, choosing technology, weighing real organizational trade-offs. Still human work.
Coding:
Works: scaffolding new modules, repetitive refactors, boilerplate, language translation, context-aware completion. Doesn’t yet: novel algorithms, owning critical-path logic, implicit constraints outside the codebase. Treat the agent as a senior intern, not a senior engineer.
Code review:
Works: flagging common issues, summarizing diffs, checking conventions, drafting first-pass review comments. Doesn’t yet: judging architectural fitness, catching subtle security or concurrency bugs, replacing the reviewer of record.
Testing: Works: generating unit test scaffolds, expanding edge cases, drafting fixtures, summarizing failure patterns. Doesn’t yet: meaningful integration tests for novel features, exploratory testing, owning regression-risk judgment.
CI/CD and deploy:
Works: triaging build failures, suggesting pipeline fixes, generating deploy notes, drafting rollback plans. Doesn’t yet: owning the deploy decision in regulated or high-risk environments.
On-call and operations:
Works: incident summarization, log triage, drafting postmortems, surfacing related past incidents, generating runbook updates. Doesn’t yet: paging decisions, escalation calls, replacing the incident commander.
Section 4: Four Patterns That Actually Ship
Four patterns consistently survive the pilot-to-production gap: the PR drafter, the on-call summarizer, the test scaffolder, and the engineering knowledge agent. Each is bounded, tied to a metric the org already tracks, and lives where engineers already work. They’re boring on purpose. Boring ships.
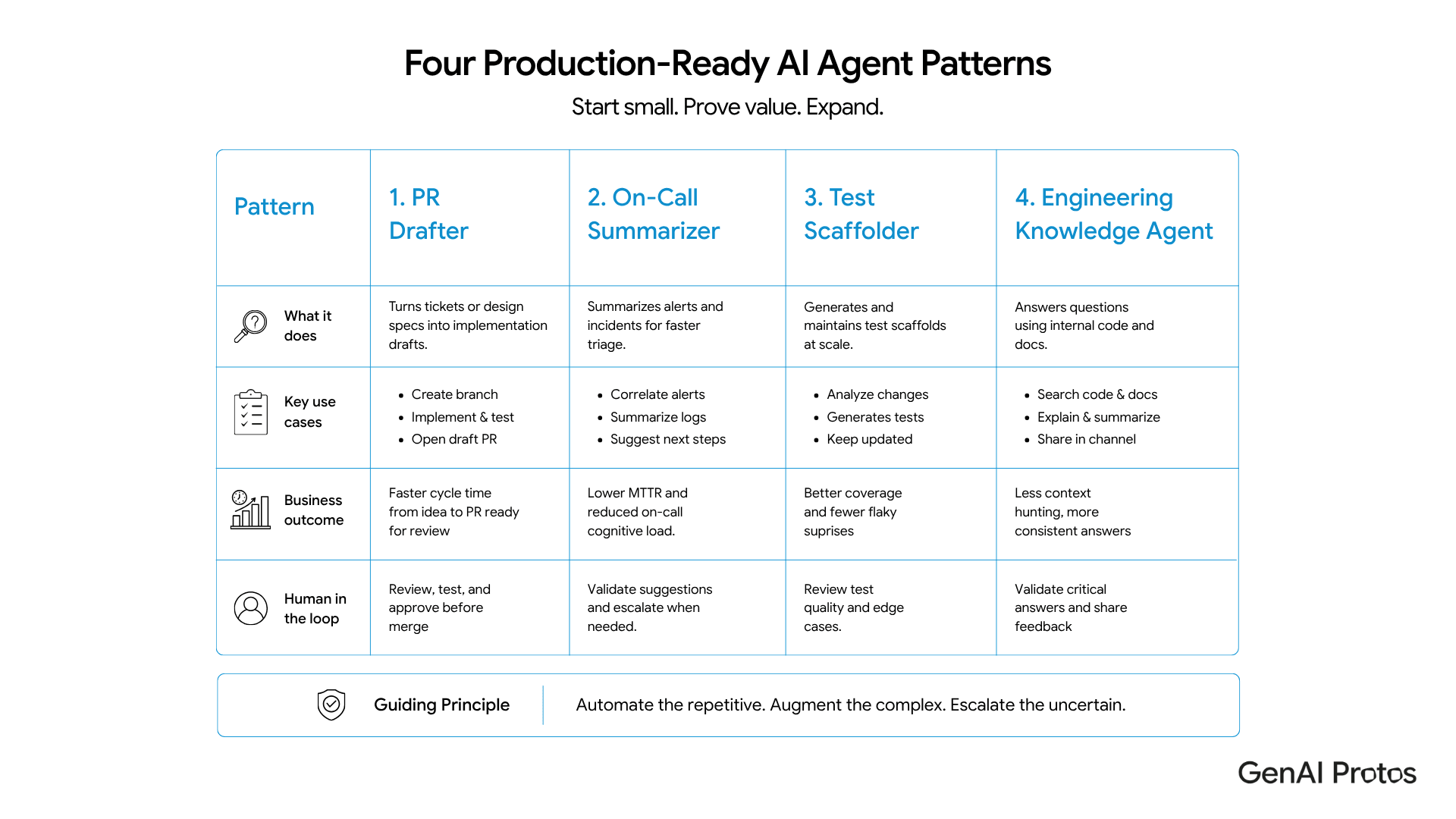
Pattern 1: The PR drafter
The agent reads a Jira ticket or design note, identifies relevant files, drafts the implementation, opens a draft PR with a written description, runs tests, and leaves the merge to a human. Optionally, it iterates on review comments. The highest-leverage pattern for most product engineering orgs in 2026 because it touches the longest, most expensive part of the lifecycle: ticket to merged PR.
Explore how a Jira-focused AI agent supports developer workflows through structured tickets, multi-tool context, and controlled automation. View the JIRA AI Agent prototype.
Pattern 2: The on-call summarizer
When an alert fires, the agent gathers context, queries logs, fetches related deploys, retrieves related incidents, drafts a triage summary, and pages the on-call engineer with a structured briefing. The win isn’t faster pages. It’s on-call engineers walking in already oriented, which compounds across every incident across every week of the year.
Pattern 3: The test scaffolder
The agent watches new PRs, identifies functions or modules without adequate coverage, drafts unit tests against existing code, runs them, fixes obvious failures, and posts suggestions on the PR. Bounded, useful, and tightly aligned with a metric most orgs already monitor: coverage trend. Easy to evaluate. Easy to roll back. Easy to defend.
Pattern 4: The engineering knowledge agent
A repository-and-docs-aware agent that lives in Slack or the IDE and answers questions like where the auth flow is defined, what changed in the billing module last sprint, or how to add a new feature flag. RAG underneath, but the value is the curated knowledge surface plus integration into the developer’s actual workflow. Quietly one of the highest-satisfaction patterns in practice, because it removes constant low-grade friction.
See how this looks in practice in our Slack AI Agent prototype, built to surface engineering knowledge inside the channels developers already use.
Section 5: What Engineering Orgs Get Wrong
The most common mistakes aren’t technical, they’re organizational: no measurement plan, treating every shape of AI tool the same, skipping guardrails, and top-down rollouts that bypass senior engineers. Treat the AI rollout like any platform deployment: clear success criteria, owned by a real team.
Rolling out without a measurement plan. Fix:
pick three metrics before the rollout. Use metrics your team already respects. Measure before and after. Anything shorter is anecdote.
Treating inline assistants and workflow agents as the same purchase. Fix:
buy them on different timelines, with different success criteria, owned by different people. Inline is individual productivity. Workflow is platform infrastructure.
Letting agents touch production without guardrails. Fix:
start read-only. Expand to draft-only PRs. Allow merging only after a defined adoption and audit period. Never give an agent production write access without a strict, audited policy layer.
Top-down rollout against senior engineers. Fix:
find the senior engineers most willing to experiment. Co-design with them. Make their feedback the gating signal. AI tools senior engineers don’t respect get politely ignored.
Optimizing for lines of code accepted. Fix:
optimize for changes that ship, not suggestions accepted. High acceptance with high downstream defects is worse than lower acceptance with clean downstream impact.
Engineering AI programs require sustained attention, not a quarterly push. The orgs that win treat it as platform investment, not a marketing line in the annual letter.
Key Takeaways
- Three shapes, three playbooks. Inline, repo-aware, and workflow agents each need their own rollout plan.
- Three layers decide success. Repo context, guardrails, and impact measurement. Skip none.
- Strong SDLC bets. Coding, review, testing, on-call, and knowledge search.
- Four patterns ship. PR drafter, on-call summarizer, test scaffolder, knowledge agent.
- Measure outcomes, not activity. Three metrics. Skip vanity signals like raw acceptance rate.
Conclusion
The demo phase is over. The next phase belongs to teams that treat AI agents as platform infrastructure: scoped, integrated, governed, and measured against outcomes the team already trusts.
Start small. One SDLC stage. One bounded pattern. Three metrics. Ship the smallest credible version. Our From Idea to AI Prototype approach is built for exactly this. Learn from real usage, then expand only where the data backs it.



