Introduction
Most enterprises reach the same AI scaling problem. A few POCs ship, a few stall, and every team has its own way of logging, evaluating quality, managing model access, and answering compliance. Leaders then ask why the next AI project still feels like a one-off.
That is the POC-to-platform moment. The goal is not to centralize every AI idea. The goal is to centralize the foundations so teams can build faster, safer, and with a shared operating model. Building the platform layer behind your enterprise AI program?
Section 1: What “AI Platform” Actually Means
An internal AI platform is the shared set of services, standards, and paved paths every AI project uses for evaluation, logging, observability, guardrails, model access, secrets, and governance. It is not a single product. It is a curated operating layer owned by a platform team and reused by application teams.
The important boundary is ownership. The platform team owns shared capabilities. Application teams still own the use case, prompt, domain data, user experience, and business workflow. When this split is clear, the platform becomes useful infrastructure. When it is blurred, the platform becomes a bottleneck.
Section 2: The Four-Stage AI Platform Maturity Model
AI platform maturity usually moves through four stages. Stage 0 is POC sprawl: each project has separate logging, evaluation, prompt formats, secrets handling, and model access. The exit move is simple: make one cross-cutting capability, usually logging or model access, shared.
Stage 1 is shared building blocks. A few services are centralized, but standards are only partly enforced. The exit move is to turn those blocks into real services with onboarding, named owners, and an SLA.
Stage 2 is a real platform with golden paths. Teams can onboard a new AI workload quickly, route through a model gateway, use standard traces, and attach guardrails without rebuilding everything. This stage needs real platform investment, but it lowers the cost of every next AI project. See our Full-Stack AI Engineering services.
Stage 3 is governed at scale. Policy, audit, PII handling, provenance, and compliance are enforced through the platform itself. The NIST AI Risk Management Framework is a useful reference point for how governance should move from documents into operating practice.
Section 3: Platform Team vs Application Team Ownership
The platform charter should be explicit. Platform teams own the reusable foundation. Application teams own the business outcome. This split prevents central bottlenecks and stops teams from rebuilding the same foundations.
| Concern | Platform team owns | Application team owns |
|---|---|---|
| Logging, tracing, observability | Infrastructure and standards | Adoption and usage |
| Evaluation | Harness and standards | Datasets and use-case metrics |
| Model gateway and access | Gateway, policies, access | Allowed model usage |
| Guardrails | Framework and default checks | Use-case configuration |
| Prompts and UX | Standards only | Full ownership |
| Domain logic and workflow | Out of scope | Full ownership |
The platform team’s job is to make the right thing the easy thing. For related delivery risks, read the seven most common AI project delivery mistakes.
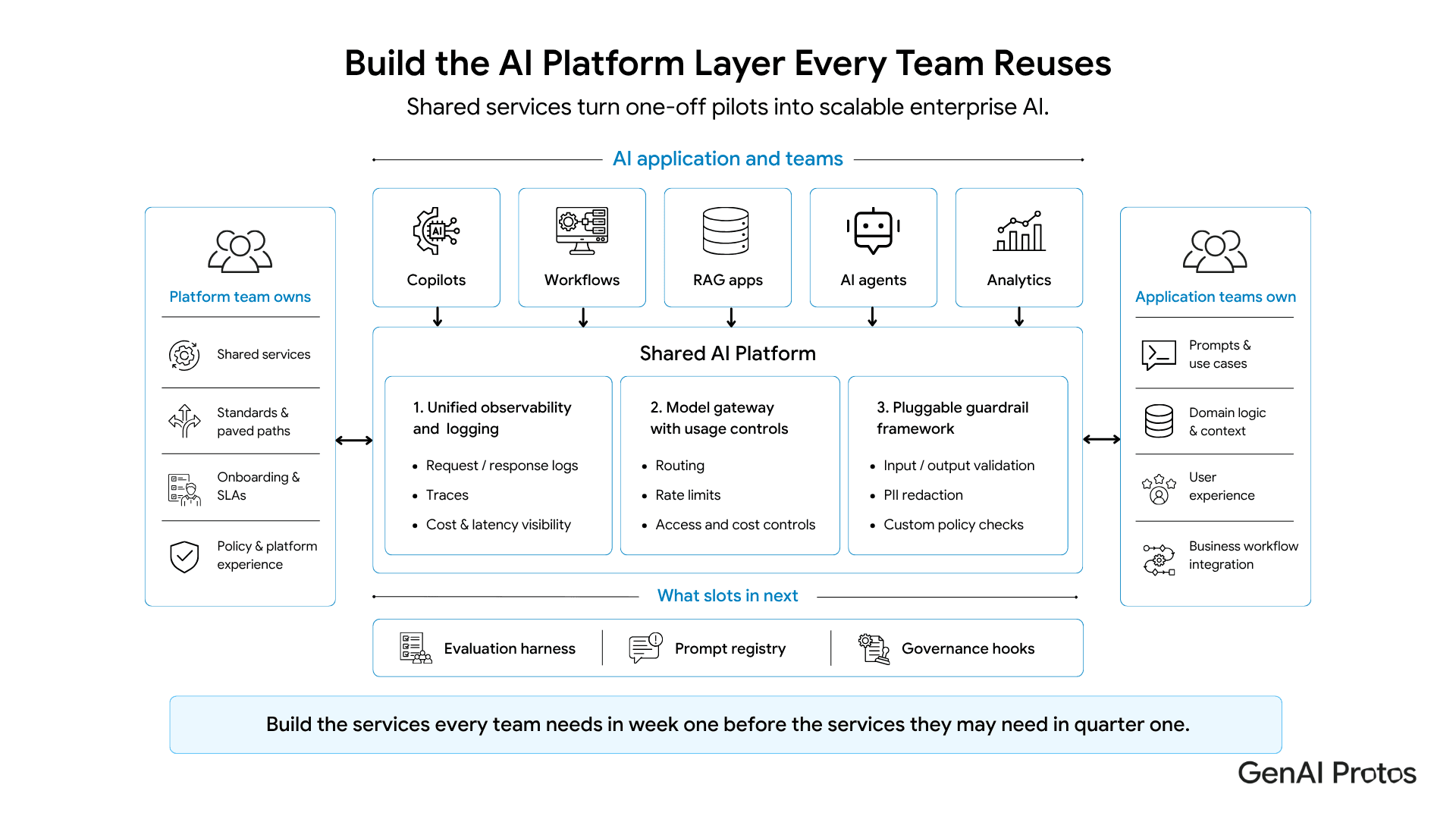
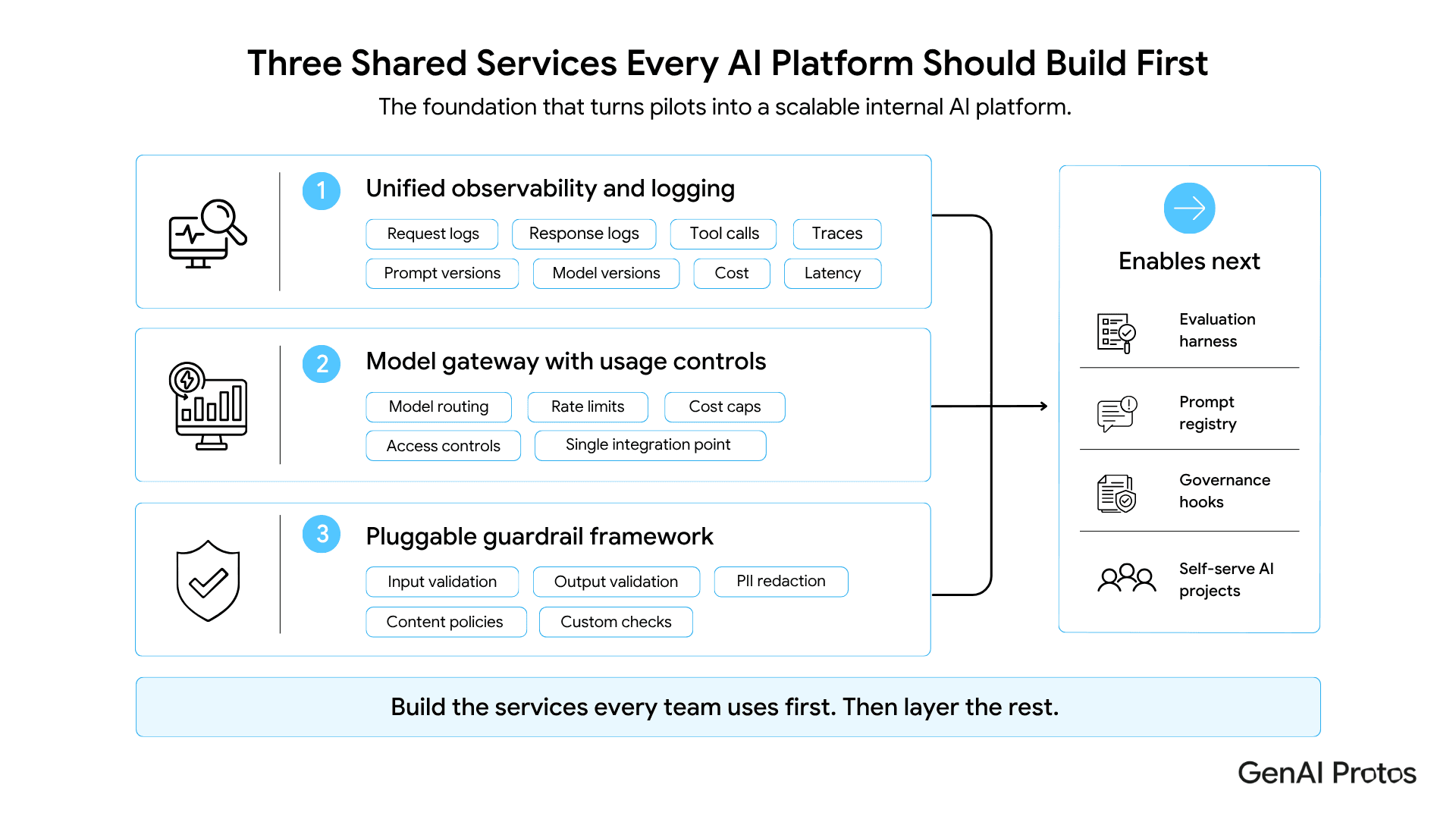
Section 4: The Three Shared Services to Build First
The first shared service should be unified observability and logging. Standardize request logs, response logs, tool calls, traces, prompt versions, model versions, cost, latency, and user context. Without this layer, the AI portfolio is a set of black boxes.
The second service is a model gateway with usage controls. Route AI traffic through one governed entry point for routing, rate limits, access controls, cost caps, and model changes. This gives teams one integration pattern and gives leadership credible usage visibility.
The third service is a pluggable guardrail framework. It should support input validation, output validation, PII redaction, content policies, and custom checks that application teams can configure for their use case. The OpenTelemetry GenAI semantic conventions are also worth considering for consistent telemetry.
Once these three services are in place, evaluation harnesses, prompt registries, and governance hooks slot in naturally. See the GenAI Protos Fact Check prototype for a practical example of grounded and evaluable AI output.
Section 5: How AI Platform Programs Stall
AI platform programs rarely fail loudly. They stall. The common patterns are predictable: platforms built without application-team input, mandates before the platform is easy to use, over-scoped first releases, under-invested second releases, and platform teams without product discipline.
The warning signs are clear. Teams route around the platform. Adoption looks good on paper, but gateway usage is low. The roadmap disappears after launch. The best metric is honest adoption: how many real workloads use the platform because it is better than the alternative.
Key Takeaways
- An internal AI platform is a shared operating layer, not a single tool.
- Maturity moves from POC sprawl to shared services, golden paths, and governed scale.
- Platform teams own reusable foundations; application teams own business logic and user experience.
- Build observability, model gateway, and guardrails before expanding into registries and governance hooks.
- Adoption is the platform metric that matters most.
Conclusion
The enterprises that scale AI are not simply choosing better models. They are building the platform layer that turns models into repeatable products. This is the work that makes evaluation, logging, cost control, governance, and compliance defensible.
The starting move is an honest stage diagnosis. Identify where your organization is today, choose the most painful cross-cutting capability, centralize that first, and earn adoption before adding the next. That is how disconnected POCs become a platform.
