Introduction
A common enterprise AI mistake starts with the sentence: “Our data platform is not ready.” Sometimes that is true. More often, it is too broad to be useful.
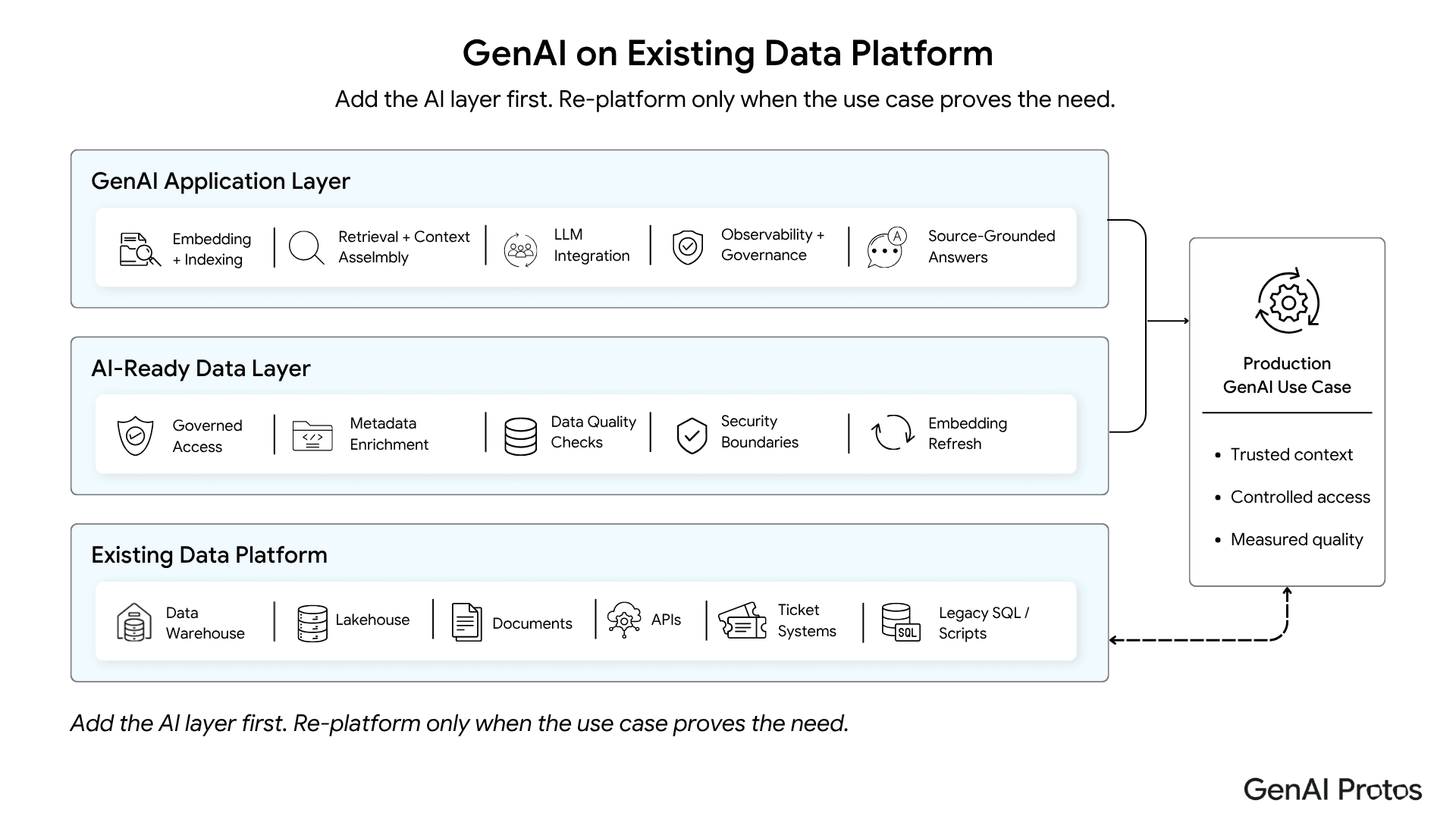
A GenAI application does not always need a new warehouse, lakehouse, or data mesh. It needs governed access to the right data, a retrieval layer that can find relevant context, an LLM layer that can answer from that context, and observability that shows whether the system is working. Those capabilities can often be added on top of the platform already in place.
This matters for CTOs and Heads of Data because full re-platforming changes the timeline from weeks to quarters or years. It also shifts focus from shipping a measurable AI use case to running a migration program. That may be justified in some cases, but it should be a decision based on evidence, not an instinct.
GenAI Protos’ AI Data Engineering Services already focus on practical layers like pipeline automation, metadata discovery, modernization, quality checks, and documentation, all of which support AI-ready data without forcing a platform replacement.
Business impact: The wrong first move can turn an AI use case into a migration program. For leadership, the decision is not whether the platform is perfect; it is whether the smallest governed layer can prove value before larger modernization spend is approved.
Why Re-Platforming First Is Usually the Wrong Move
Re-platforming feels safe because it promises a cleaner future. But in AI programs, it often delays the learning loop. You do not know which infrastructure gaps matter until the first use case tests real data, real access patterns, and real user questions.
Three assumptions usually drive unnecessary rebuilds.
1. “Our data format is not AI-ready”
Embeddings are created from readable text, records, tables, and documents. The source system does not need to “understand AI.” It needs a reliable extraction path and clear metadata.
2. “Our warehouse is too slow”
For many GenAI use cases, the warehouse is the source of record, not the query-time retrieval engine. Embeddings can be precomputed, indexed, cached, and refreshed on a schedule. The AI layer can operate without forcing every question through the warehouse in real time.
3. “We need a vector database first”
A vector store can be important, but it is not always the first move. The better sequence is: validate the use case, test retrieval quality, understand latency, then decide whether a dedicated vector layer is necessary.
The practical question is not “Is the whole platform AI-ready?” The better question is: What is the minimum governed layer required to ship this AI use case safely?
The Five Layers Needed to Add GenAI
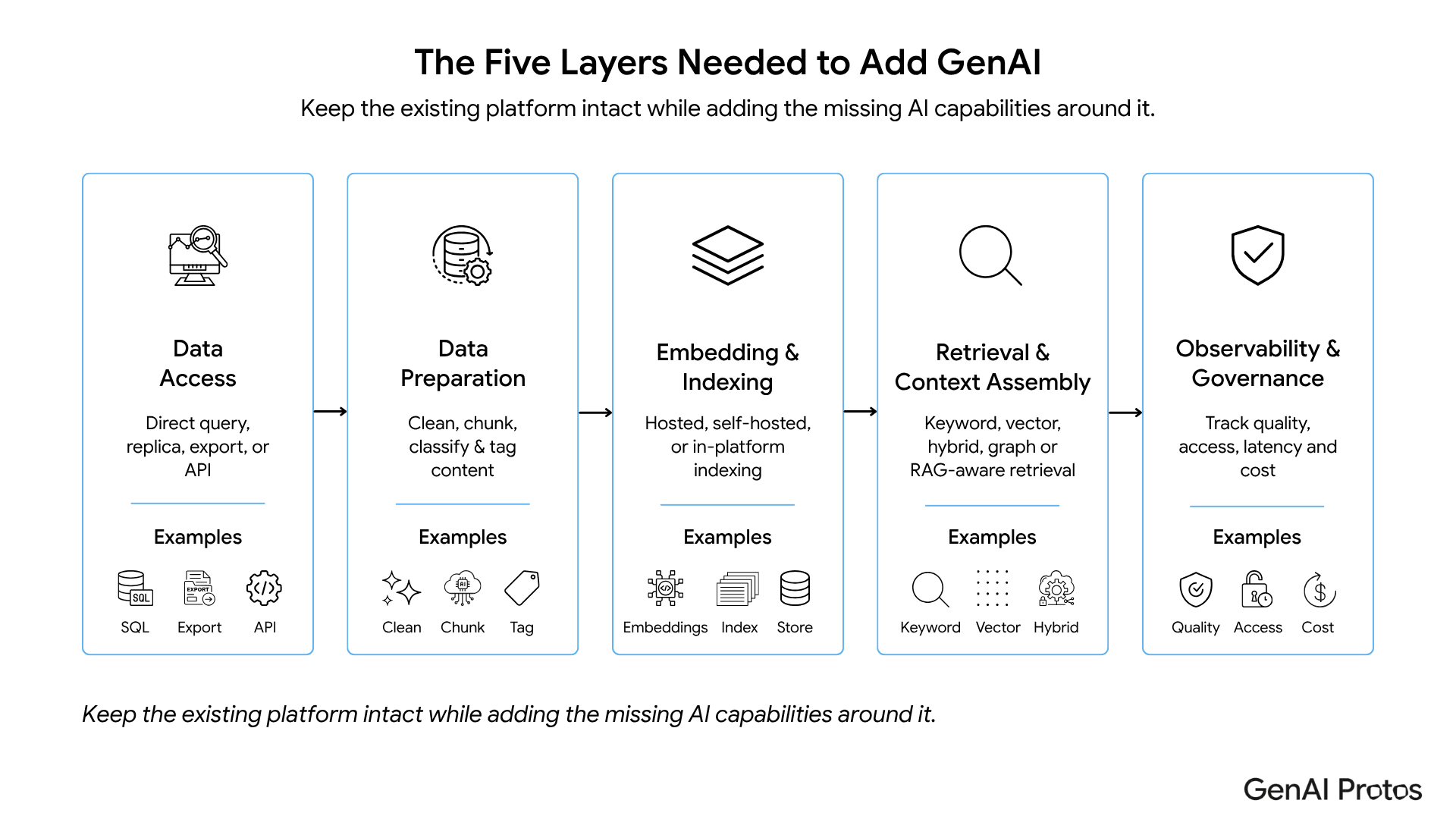
A workable GenAI layer on existing data usually needs five components.
| Layer | Purpose | Decision point |
|---|---|---|
| Data access | Read the required sources safely | Direct query, replica, export, or API |
| Data preparation | Clean, chunk, classify, and tag content | What metadata and quality checks are required? |
| Embedding and indexing | Convert content into searchable representations | What metadata and quality checks are required? |
| Retrieval and context assembly | Fetch useful context for each question | Hosted, self-hosted, or in-platform indexing |
| Observability and governance | Track quality, access, latency, and cost | Keyword, vector, hybrid, graph, or SQL-aware retrieval |
| What must be logged and reviewed? |
This model keeps the existing platform intact while adding the missing AI capabilities around it.
For example, if documentation is weak, the right fix may be metadata enrichment, not migration. GenAI Protos’ work around automating data documentation is directly relevant because undocumented data is often the real blocker behind “platform readiness.”
Extend, Modernize, or Re-Platform
Use this decision table before committing to a platform overhaul.
| Path | Choose it when | Avoid it when |
|---|---|---|
| Extend existing platform | Data is accessible, governed, and usable for a first AI use case | Core access paths are broken or blocked |
| Selectively modernize | One or two gaps block the use case, such as metadata, connectors, or access control | The team is using “modernization” as a vague rewrite |
| Full re-platform | The current platform is end-of-life, unsafe, inaccessible, or already planned for retirement | The only reason is “AI might need it later” |
A good CTO-level decision process is simple:
Pick one priority use case.
Identify required data sources.
Validate programmatic access.
Test retrieval quality on sample queries.
Assess compliance and security constraints.
Choose the smallest platform change that enables safe production.
If your foundation problem is broader than a single use case, GenAI Protos’ guide on why the data foundation layer holds back AI ambitions is a useful internal link for readers.
What This Looks Like in Enterprise Environments
Financial services knowledge assistant
A regulated team may keep customer and policy data in the existing platform, add a controlled retrieval layer, and route sensitive workflows through private or self-hosted inference. The value comes from making governed data usable, not moving it somewhere new.
Manufacturing field support
Maintenance logs, service manuals, and asset records may sit across lakehouse tables, PDFs, and ticket systems. A GenAI layer can unify them through extraction, chunking, retrieval, and source-grounded answers.
Data engineering modernization
Existing SQL, stored procedures, and legacy scripts often contain years of business logic. Rather than replacing them blindly, teams can analyze and modernize them with AI-assisted conversion workflows. GenAI Protos’ SQL-to-PySpark migration solution is a relevant internal example because it works with existing data assets instead of assuming they must be discarded.
Common Failure Modes
Treating data access as solved
Data may exist, but access may fail under production permissions. Validate service accounts and network routes early.
Skipping metadata work
Poor metadata weakens retrieval, access control, and answer traceability. Fix metadata before blaming the model.
Ignoring refresh cadence
Embeddings go stale when source data changes. Define refresh rules as part of the first build.
Starting with platform debates instead of use cases
A use case creates clear requirements. A platform debate creates opinions.
No observability from day one
Without logs for query, retrieved context, response, and quality score, teams cannot improve the system reliably.
GenAI Protos’ Smart Data Modeling work is a useful supporting link here because strong modeling and documentation directly improve AI retrieval and governance.
Key Takeaways
You can often add GenAI to the existing platform without full migration.
The minimum stack is data access, preparation, embedding, retrieval, and observability.
Re-platforming should be evidence-based, not fear-based.
Metadata and documentation are often bigger blockers than storage technology.
Start with one use case, ship safely, measure quality, then modernize selectively.
Conclusion
GenAI does not require every enterprise to rebuild its data estate first. It requires clear data access, clean enough context, governed retrieval, reliable model integration, and quality monitoring. Those layers can often be added without replacing the systems that already run the business.
The strongest teams extend first, learn from production, then modernize where evidence shows a real bottleneck. That creates a better AI roadmap and a better data roadmap.
Run GenAI on Your Existing Stack: No Platform Overhaul Required
GenAI Protos builds AI layers on top of existing enterprise data platforms, with practical engineering around access, retrieval, governance, and observability.
Start the conversation


