Table of Contents
- The Compliance Research Problem Nobody Talks About
- Why a Standard RAG Pipeline Is Not Enough
- Architecture Overview: Treating Every Query as a Planning Problem
- Inside the Agent Layer: Six Engineering Decisions That Defined the System
- The Full Technology Stack
- Results: What Actually Changed for the Compliance Team
- What We Learned Building Agentic AI for a Regulated Institution
- Key Takeaways
- Conclusion
- FAQ
The Compliance Research Problem Nobody Talks About
When a product team at a Tier-1 bank asks their compliance officer "does the new sustainability disclosure rule apply to our SME lending book given the latest amendment?", that question looks simple. It is not.
Answering it defensibly requires identifying the parent regulation, locating the amendment, resolving the applicability threshold, cross-referencing any jurisdictional transposition, checking the internal policy interpretation memo, and documenting every step with clause-level citations because a verbal answer without an audit trail is not a compliance answer. It is a liability.
Compliance teams at this institution were spending hours doing exactly that work for every non-trivial product question. Five browser tabs open. Cross-referencing by hand. Thousands of regulations, directives, and amendments to track most of which interlock and reference each other across jurisdictions. And regulation does not slow down while teams catch up.
Four pain points repeated week after week:
- Volume and complexity - thousands of live regulations, directives, and amendments, the majority referencing each other across documents and jurisdictions
- Scattered sources - legal content fragmented across primary regulator publications, jurisdictional transpositions, secondary guidance, and internal policy memos
- Manual research bottleneck - senior compliance staff doing hours of cross-referencing to answer questions that should take minutes
- Risk of oversight - missing a regulatory update or misreading a clause means non-compliance penalties and reputational damage a keyword search is not a defensible process
The institution needed a system that could reason across documents and prove it had reasoned correctly. That is a different capability requirement than search.
Building AI for a regulated institution? Download our BFSI AI Architecture Decision Guide a framework used by compliance and engineering teams to evaluate agentic AI readiness and scope their first production build.
Why a Standard RAG Pipeline Is Not Enough
Quick answer: Standard RAG chunk the corpus, embed it, retrieve top-k, hand it to an LLM collapses under serious compliance workloads for three structural reasons: compliance questions are multi-hop, the regulatory corpus is continuously updated, and citation discipline is non-negotiable for audit use. Vanilla RAG fails on all three.
This is worth unpacking precisely, because "we tried RAG and it wasn't good enough" is often hand-waved. Here is exactly where the failure modes appear:
Reason 1- Compliance Questions Are Multi-Hop
A query like "Does the new sustainability disclosure rule apply to our SME lending book given the latest amendment?" is not a retrieval problem. It is a reasoning problem that happens to require retrieval at multiple steps:
- Identify the relevant sustainability disclosure regulation
- Locate the specific amendment referenced
- Resolve the applicability threshold in that amendment
- Reason about whether the SME lending book falls within scope
- Check for any internal policy interpretation that overrides or refines the regulatory default
A single embedding lookup against a pre-indexed corpus returns text that looks relevant. It returns the chunk nearest the query vector which might be the general disclosure rule, not the amendment that changes its scope. The model then reasons over incomplete evidence and produces an answer that is plausible, confident, and wrong.
Reason 2 - The Corpus Moves Underneath You
Regulators publish updates, consolidated versions, and Q&A guidance continuously. Any ingest-and-index architecture is, by construction, running behind the live law.
For most enterprise knowledge bases, a one-week-old index is acceptable. For compliance, an answer grounded in a superseded version of a regulation is worse than no answer it actively misleads the compliance officer and creates audit exposure. Pre-indexed RAG architectures have no clean solution to this problem. Live retrieval does.
Reason 3 - Citation Discipline Is Non-Optional in Compliance
A compliance answer without clause-level citations is unusable as an audit artifact. Full stop.
Vanilla RAG can surface relevant passages, but it cannot enforce that every sentence in the generated answer maps to a verifiable passage in a live source. The model might synthesise across passages, introduce a clause that sounds right but has no source, or paraphrase in a way that changes meaning. None of that is detectable without a verification layer.
In a consumer application, that failure mode is a UX problem. In BFSI compliance, it is a regulatory exposure.
The architectural call: Stop trying to flatten regulation into a vector store. Treat each query as a planning problem, give the system tools to navigate live sources, and enforce that every sentence in the answer is anchored to a citation it can re-fetch on demand.
Architecture Overview: Treating Every Query as a Planning Problem
The Compliance Intelligence Platform processes every query through a deterministic, step-based multi-agent workflow not a free-form agent loop. Six steps, from natural-language input to cited answer:
The pipeline runs as a deterministic, step-based workflow not a free-form ReAct loop. This was a deliberate architectural choice. Compliance Q&A is a repeatable process. Step-based execution produces auditable checkpoints at every stage. A free-form agent trace, by contrast, is difficult to audit because the reasoning path is not predetermined and checkpoints are not guaranteed.
We started with a free-form agent design. We moved deliberately to step-based workflows. The system got more reliable, and far easier for second-line teams to review.
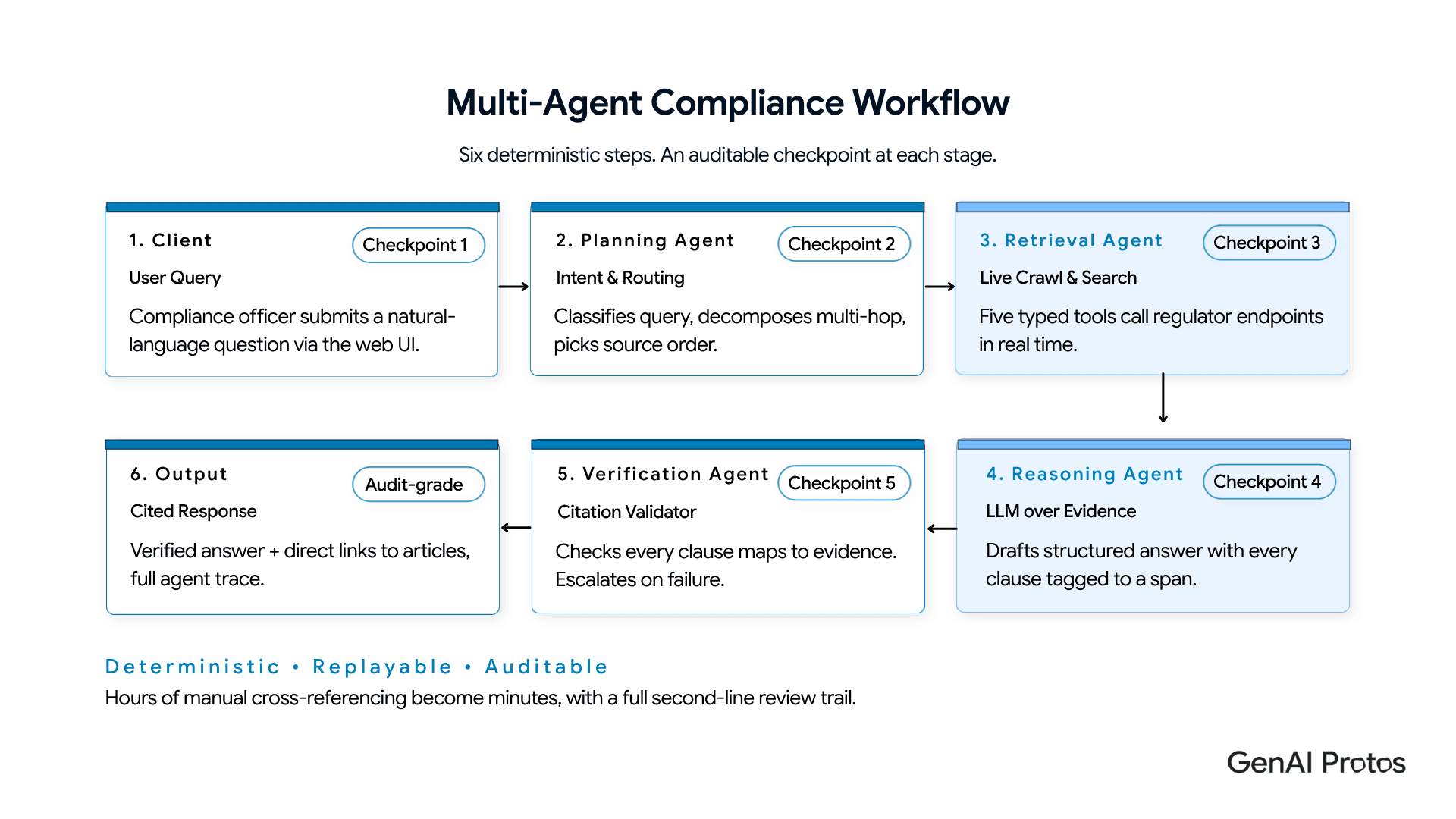
Inside the Agent Layer: Six Engineering Decisions That Defined the System
Decision 1- Framework: Why We Chose Agno
We evaluated LangGraph, CrewAI, AutoGen, and Agno for multi-agent orchestration. All four can build deterministic step-based workflows. The differentiator was operational: Agno is lightweight, fast, and ships with a production runtime out of the box (AgentOS).
In a compliance workload, every query already pays the latency cost of live retrieval across multiple regulator endpoints plus a multi-step reasoning loop. A heavy framework runtime adds overhead at exactly the wrong place. Agno's small per-step footprint kept per-query latency within the range compliance analysts would accept as "fast enough to use."
AgentOS also provides the API surface, streaming, RBAC/JWT authentication, and session persistence that an enterprise deployment requires which kept the engineering team focused on the compliance problem rather than rebuilding scaffolding.
Decision 2- Five Narrow, Typed Tools (Not an Omnibus Search)
The retrieval surface is wrapped by exactly five Pydantic-typed tools. Each does one thing:
| Tool | Purpose |
|---|---|
| Primary Retrieval | Queries authoritative primary regulator endpoints in real time |
| Secondary Source | Fetches supplementary guidance documents |
| Section / Article Lookup | Resolves a specific article or paragraph within a regulation |
| Cross-Reference | Follows internal citation links between regulatory documents |
| Date / Version Resolution | Ensures the agent reasons over the version of the rule in force on the relevant date not the most recently published version |
The date/version tool deserves specific attention. In compliance, "which version applies" is not a metadata question it is a substantive legal question. A disclosure rule that was amended six months ago may have a transitional provision making the old version apply to legacy products. Resolving that correctly requires a dedicated tool that understands effective-date logic, not a general search that retrieves the latest document.
Narrow, typed tools produced cleaner audit trails and more predictable behaviour than any omnibus search approach we prototyped. The tool call record is itself an audit artifact it shows exactly which sources the agent consulted, in what order, with what parameters.
# Example: Pydantic-typed tool definition for date/version resolution
from pydantic import BaseModel
from typing import Optional
from datetime import date
class DateVersionInput(BaseModel):
regulation_id: str # e.g. "EU/2022/2554" (DORA)
query_effective_date: date # the date for which applicability is assessed
jurisdiction: str # e.g. "IE", "DE", "EU"
include_transitional: bool = True # whether to resolve transitional provisions
class DateVersionOutput(BaseModel):
version_in_force: str # the specific version applicable on query_date
effective_from: date # when this version came into force
supersedes: Optional[str] # prior version ID if applicable
transitional_notes: Optional[str] # any transitional provisions relevant
source_url: str # direct link to the authoritative version
retrieved_at: str # ISO timestamp when the tool fetched this
# The tool call itself becomes a line in the audit trail:
# "On [timestamp], the agent checked DORA version in force on [effective_date]
# for jurisdiction [IE] resolved to version [X], effective [date], source [URL]"
Decision 3 - Two-Tier Memory Architecture
Memory operates at two distinct tiers, each serving a different purpose:
Working state (within a single workflow run): Evidence retrieved by any agent in the team is written to shared workflow state and is immediately available to all subsequent agents. This prevents redundant retrieval calls to live regulator end points a practical concern both for latency and for being a responsible API consumer against official sources.
Cross-session memory (persisted): What questions analysts have previously asked, which regulations they regularly reason over, and resolved citation patterns are persisted across sessions. This surfaces relevant regulatory history when an analyst asks a question similar to one the system has answered before.
Session checkpointing: Sessions checkpoint to a Postgres store. An interrupted query can resume from its last completed step rather than restarting from scratch which matters for the multi-hop chains that can take several seconds per step.
Decision 4 - Guardrails and Hallucination Controls
This is where the project lived or died. Four controls stack on top of each other:
Post-execution clause check (hardest gate): The composer agent runs a post-execution check that rejects any clause in the final answer that does not have an attached evidence span from a retrieved source passage. No span, no clause the sentence is either rewritten against available evidence or removed. This is the primary mechanism that makes every answer audit-grade.
Confidence-scoring guardrail: A confidence score is computed for each answer segment based on source retrieval quality and evidence span coverage. Answers below threshold are labelled "needs human review" rather than returned with false confidence. In compliance, an uncertain answer labelled as certain is more dangerous than no answer.
Human-in-the-loop escalation: When authoritative evidence is genuinely missing the regulation has not been fetched, or the question requires judgment beyond the retrieved evidence the query routes to a named senior analyst rather than the system improvising. The escalation path was designed early in the build, not added as an afterthought.
Input-side guardrails: PII detection and prompt-injection defence run before the planning agent ever sees the query. This is standard hygiene for enterprise LLM deployments but particularly important in a compliance context where queries frequently contain sensitive client or transaction details.
# Simplified post-execution clause validation
def validate_answer_clauses(answer: AnswerDraft, evidence_store: EvidenceStore) -> ValidationResult:
"""
Reject any clause in the answer that cannot be grounded
to a specific passage in the retrieved evidence store.
Returns: ValidationResult with approved_clauses and rejected_clauses
"""
approved = []
rejected = []
for clause in answer.clauses:
# Each clause must carry an evidence_span_id assigned during reasoning
if not clause.evidence_span_id:
rejected.append(RejectedClause(
text=clause.text,
reason="no_evidence_span",
action="rewrite_or_remove"
))
continue
# Verify the span actually exists in the retrieved evidence
span = evidence_store.get_span(clause.evidence_span_id)
if span is None:
rejected.append(RejectedClause(
text=clause.text,
reason="span_not_in_evidence_store",
action="escalate_to_human"
))
continue
# Semantic similarity check: does the clause actually follow from the span?
similarity = compute_entailment_score(clause.text, span.passage_text)
if similarity < ENTAILMENT_THRESHOLD:
rejected.append(RejectedClause(
text=clause.text,
reason=f"low_entailment_score:{similarity:.2f}",
action="rewrite_against_span"
))
continue
approved.append(ApprovedClause(text=clause.text, span=span))
return ValidationResult(approved=approved, rejected=rejected)
Decision 5 - Observability via Portkey AI Gateway
Every LLM call routes through Portkey as the AI gateway and observability layer. Portkey captures full request/response traces, model routing decisions, retries, cost telemetry per query, and latency per step.
Combined with Agno's workflow-level traces covering every tool call, retrieved passage, and verification outcome the result is a per-query record of every reasoning step the system took. This record is usable not just by engineers debugging a wrong answer, but by audit teams reviewing how a specific answer was derived weeks later.
Without per-query traces, debugging a wrong compliance answer is archaeology. Observability was treated as core build infrastructure from day one, not a post-launch addition.
Decision 6 - Evals Built Into the Development Cycle
Accuracy and reliability evaluations ran from week one, not at UAT. Two evaluation tracks ran in parallel throughout the build:
LLM-as-a-judge accuracy evals: A separate LLM judge evaluated answer accuracy against a gold-standard question set curated by the compliance team covering the regulation types and question patterns most common in the institution's workload. Running these continuously meant prompt changes or tool modifications that degraded accuracy were caught within the sprint, not at user acceptance testing.
Tool-call verification evals: Automated checks on whether the agent called the right tools, in the right order, with the right parameters for a given question type. These caught failure modes in the planning agent cases where the intent classifier miscategorised a query and routed retrieval to the wrong source tier that accuracy evals alone would have missed.
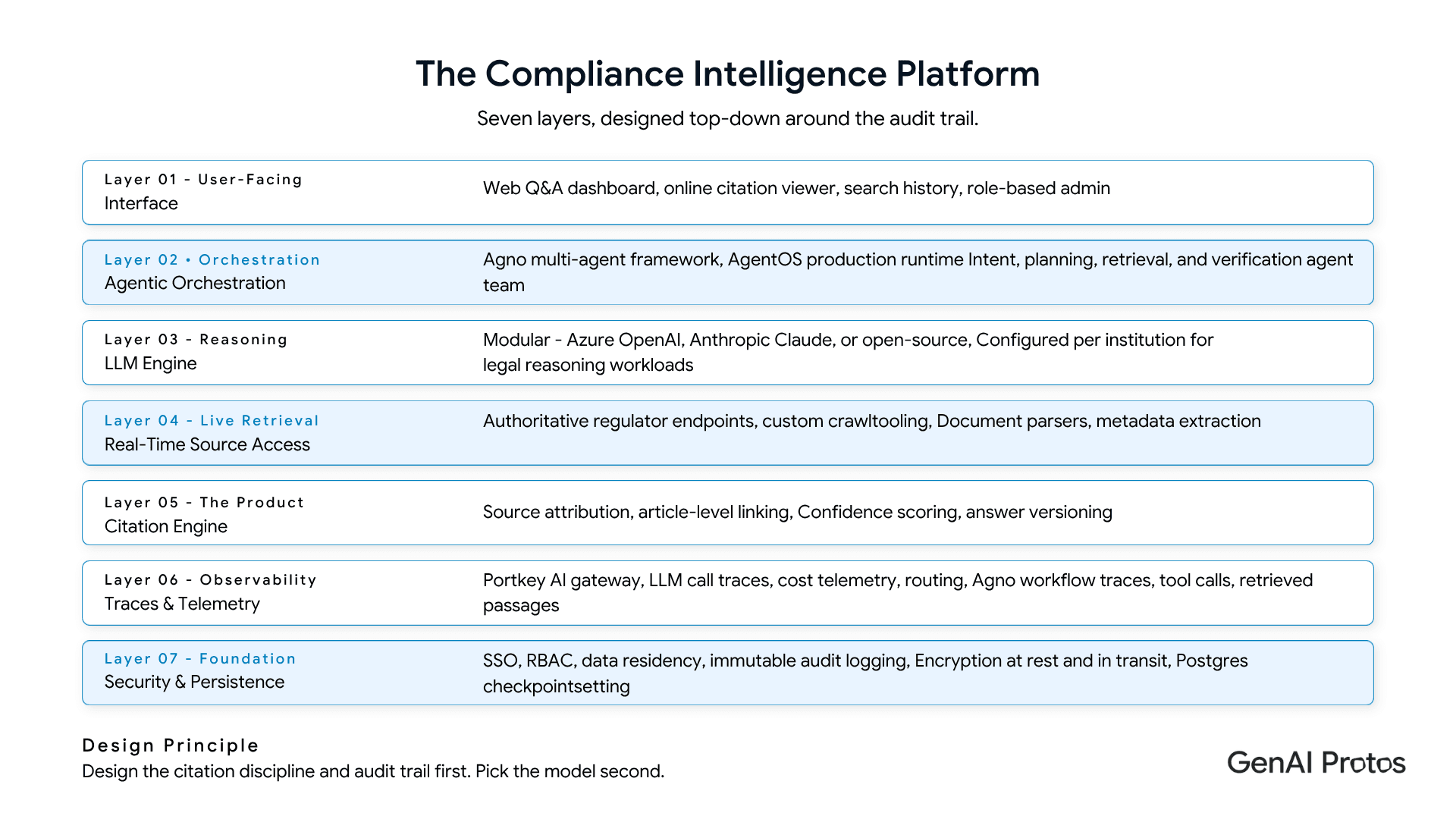
The Full Technology Stack
The platform is structured across seven functional layers:
| Layer | Components |
|---|---|
| Real-Time Source Access | Authoritative regulator endpoints · Custom crawl & query tooling · Document parsers · Metadata extraction |
| Agentic Orchestration | Agno multi-agent framework · AgentOS production runtime · Intent, planning, retrieval, verification agent team |
| LLM Engine | Azure OpenAI / Anthropic Claude / open-source (configurable) - optimised for legal reasoning tasks |
| Citation Engine | Source attribution · Article-level linking · Confidence scoring · Answer versioning |
| Caching Layer | Smart caching for frequently queried regulations · TTL-based invalidation · Graceful fallback when source endpoints are degraded |
| Interface | Web-based Q&A dashboard · Inline citation viewer · Search history · Saved queries · Alerts · Role-based admin panel |
| Security & Compliance | Region-appropriate data residency · SSO/RBAC · Immutable audit logging · Encryption at rest and in transit |
| Observability | Portkey AI gateway (LLM call traces, cost telemetry, routing) · Agno workflow traces (tool calls, retrieved passages, verification outcomes) |
| Persistence | Postgres for session checkpointing and cross-session memory |
The modular LLM engine is worth highlighting explicitly. The platform is not locked to a single model provider. It is configured at deployment time to route legal reasoning tasks to whichever model performs best against the institution's specific regulatory domain Azure OpenAI, Anthropic Claude, or a fine-tuned open-source model running inside the institution's own security boundary. For BFSI clients with strict data-residency requirements, the open-source routing option is often the right call.
Common pitfall: Teams building compliance AI often choose their LLM first and design their architecture around it. For regulated industries, the correct sequence is the opposite: design the citation discipline and audit trail architecture first, then select the model that fits inside it. Model choice is a configuration decision; audit trail design is an architectural commitment.
Results: What Actually Changed for the Compliance Team
The platform replaced the slowest and most error-prone parts of the compliance workflow. Four outcomes defined the business impact:
Query resolution time collapsed from hours to minutes. Routine compliance lookups that required hours of manual cross-referencing now resolve in minutes. The platform does not just answer faster it does the retrieval, cross-referencing, and citation work that consumed the bulk of the time.
Senior analyst capacity freed for genuinely novel work. First-line interpretation queries the well-defined, high-volume questions that compliance teams handle repeatedly are now handled by the platform. Senior analysts focus on novel regulatory questions, policy interpretation edge cases, and the escalated queries the system correctly recognises it cannot answer with high confidence.
Accuracy becomes demonstrable, not asserted. Every answer is bound to live source passages with clause-level citations. The institution can demonstrate accuracy on a per-clause basis not just claim it. This changes the conversation with internal audit from "we trust the AI" to "here is the evidence trail for this specific answer."
Full agent traces as audit artifacts. Per-query traces capture every tool call, every retrieved passage, every verification step, and every model decision. Second-line defence teams can reconstruct exactly how any answer was derived the same audit standard applied to human analysts is now applicable to AI-generated answers.
"The question was never whether the AI could answer. It was whether the institution could defend the answer." Compliance Platform Architect, Tier-1 Bank
What We Learned Building Agentic AI for a Regulated Institution
Six lessons emerged from the build that we carry into every subsequent regulated-industry engagement:
1. Deterministic workflows beat free-form agent loops for regulated work. Determinism, replayability, and step-level traces matter more than agent autonomy when auditability is a hard requirement. We started free-form. We moved to step-based. The system became more reliable and significantly easier for non-engineering audit teams to review.
2. Tool boundaries matter more than tool count. Five narrow, Pydantic-typed tools outperformed every broad search tool we prototyped in trace quality, in predictability, and in the debuggability of failure cases. The tool call log is an audit artifact. Narrow tools make that log legible.
3. Observability is non-negotiable. Without per-query agent traces, debugging a wrong answer is archaeology. We treated observability as core infrastructure not a post-launch addition. Portkey + Agno traces meant we could pinpoint the exact tool call or reasoning step where a failure originated.
4. Evals belong in the build cycle, not after it. Running LLM-as-a-judge accuracy evals and tool-call verification evals from week one caught regressions inside sprints. Teams that defer evals to UAT discover they have been shipping degraded accuracy for months.
5. Live retrieval beats pre-indexed corpora for live regulation. An index is stale the moment a new amendment publishes. For compliance, the architecturally honest choice is real-time grounded retrieval. The engineering overhead is real. The alternative answering compliance questions from a corpus that may be weeks behind the law is not acceptable.
6. Design the escalation path before you design the autonomy. Human-in-the-loop escalation was designed into the workflow from the first architecture review. The system's reliability comes partly from its willingness to say "I cannot answer this with sufficient confidence here is the right person to ask." That behaviour cannot be retrofitted; it has to be architectural intent from day one.
Key Takeaways
- Agentic AI for compliance outperforms standard RAG on the three dimensions that matter in regulated industries: multi-hop reasoning, live corpus access, and enforceable citation discipline
- Deterministic step-based workflows are the correct architecture for regulated workloads they produce the auditable checkpoints that second-line teams and regulators require
- Five narrow, typed tools beat an omnibus search tool the tool call log is an audit artifact; make it legible
- Every answer must be clause-level cited not as a feature, but as an architectural hard gate enforced by the verification agent
- Per-query observability (Portkey + Agno traces) is core infrastructure, not a nice-to-have without it, debugging wrong answers in a live compliance system is not feasible
- Human-in-the-loop escalation is a design feature, not a fallback the system's credibility rests on its willingness to escalate when uncertain
Conclusion
In a regulated industry, the question is not "can the model answer this?" it is "can the institution defend the answer?" That reframes the entire technology choice.
Agentic AI earns its place in BFSI compliance for four reasons that are architectural, not cosmetic. Multi-hop reasoning is native to agent workflows where it is structurally impossible for flat retrieval. Auditability is built in every agent trace is a contemporaneous record of how an answer was derived, the exact artifact internal audit and regulators want. Tool-use transparency means the system's actions are inspectable and explainable, not a black box. And graceful degradation escalating when uncertain rather than hallucinating with confidence is the right safety behaviour for a domain where a wrong answer is a compliance event.
The deepest bet in this architecture is straightforward: in regulated industries, the most defensible AI is the one that can show its work and an agent's trace is that work.
We built this system for one of the most established banking groups in our market. It is in production. The compliance team uses it daily. The audit trail holds up.
