Introduction
A fully local voice agent runs the entire speech pipeline, capture, transcription, reasoning, and synthesis, on hardware you control. No audio leaves your network. For teams in finance, healthcare, defense, and any operation handling regulated voice data, that has shifted from a nice-to-have to a baseline requirement. Cloud voice APIs are convenient, but they ship raw user audio to third parties and bill per minute, both of which are increasingly hard to defend in a procurement review.
In our work building production voice systems, the question we hear most often is whether a fully on-prem stack can match cloud quality without breaking the latency budget for real conversation. The honest answer is yes, with the right model choices and a clean pipeline. This post walks through the stack, the architecture, and the numbers from a recent multilingual deployment.
Voice AI that never leaves your network. Explore our local multilingual voice agent solution built for regulated and privacy-sensitive teams:
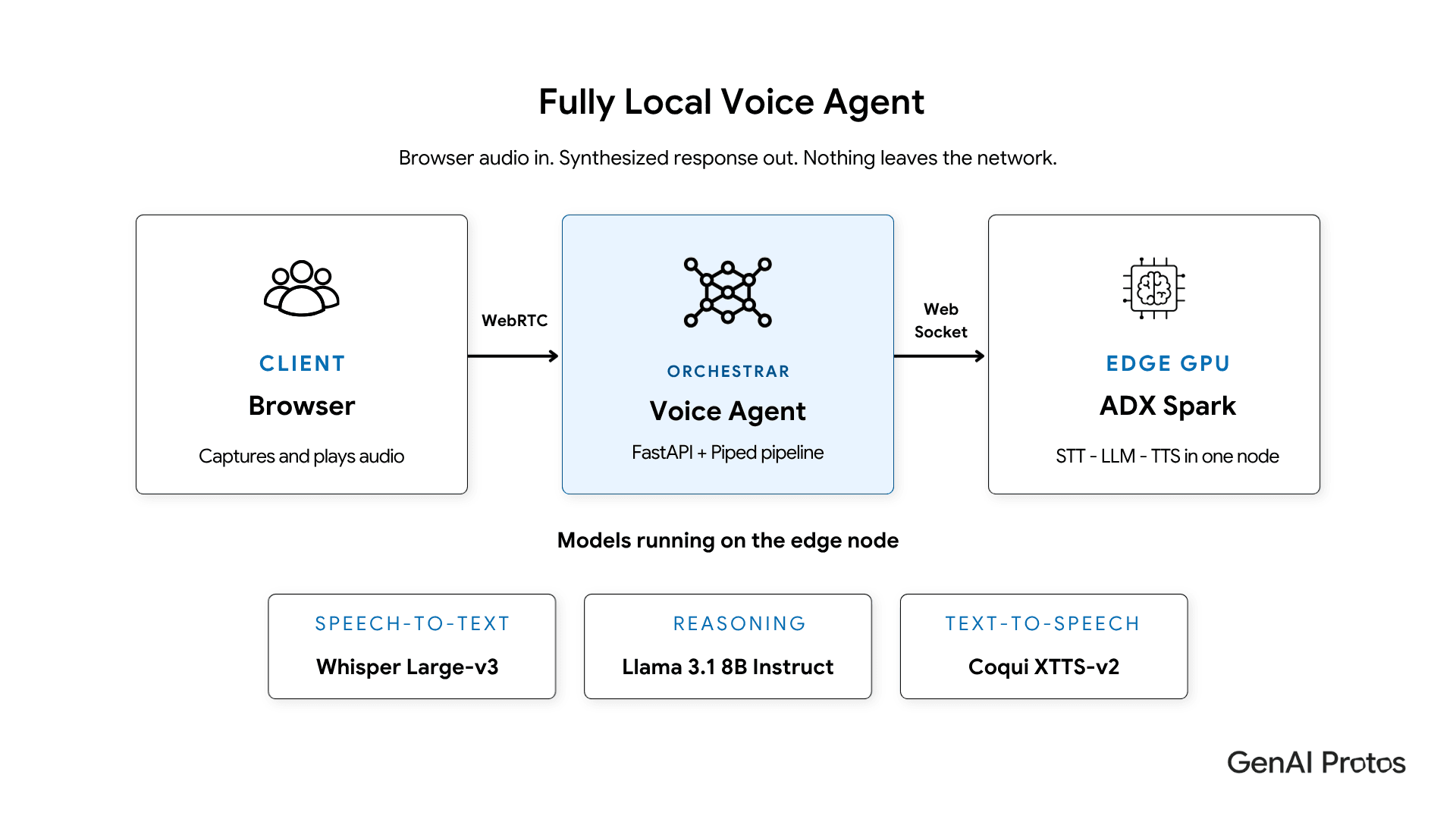
What Is a Fully Local Voice Agent?
A fully local voice agent is a real-time conversational AI system in which speech-to-text, language model reasoning, and text-to-speech all run on hardware inside your own network instead of a third-party cloud. The user's audio, transcripts, and model responses never leave the local environment, which is what makes the system suitable for regulated and privacy-sensitive use cases.
In practice, that usually means three services running on a GPU appliance such as an NVIDIA DGX Spark or a Jetson-class edge device, plus a thin orchestration layer that handles WebRTC audio with the browser. The browser still gets a clean, low-latency conversational experience. The audit trail stays inside your VPC.
This is a different design point from a self-hosted chatbot. Voice introduces strict timing budgets and audio I/O concerns that text systems do not have, and the model choices have to reflect that.
Why Enterprises Are Moving Voice AI to the Edge
Three pressures push voice workloads on-prem: data residency, cost, and resilience. Public voice APIs typically log audio for abuse monitoring and model improvement. Even with enterprise tiers, that creates a chain of custody that compliance, security, and legal teams have to underwrite. For HIPAA-covered workloads, regulated finance, and EU operations under GDPR and the AI Act, a local voice agent removes the hardest questions in the review.
Cost is the second driver. Cloud voice pipelines often combine separate STT, LLM, and TTS billing, each priced per minute or per token. A voice assistant handling a few thousand conversations a day can quietly become a five-figure monthly line item. A single GPU node running Whisper, Coqui XTTS, and Llama 3.1 8B handles that load with no per-minute fee.
The third driver is resilience. A local voice stack works on a closed network, in a hospital basement, on a factory floor, or in a branch office with intermittent connectivity. That matters for any operation where downtime is not optional.
If you want a deeper view of the trade-offs between on-prem and cloud generative AI, our private AI vs cloud AI breakdown walks through the decision criteria in detail.
Custom private AI and edge solutions. See how GenAI Protos delivers private AI and edge deployments for finance, healthcare, and government operations:
The Stack: Whisper Large-v3, Coqui XTTS-v2, and Llama 3.1 8B
The model choices for a production local voice agent are tightly constrained. You need genuinely multilingual STT, natural sounding TTS with consistent voice, and an LLM small enough to fit alongside both on a single GPU node while still holding up in conversation. Whisper Large-v3, Coqui XTTS-v2, and Llama 3.1 8B Instruct are the combination we have shipped most often.
Speech-to-Text with Whisper Large-v3
Whisper Large-v3 is OpenAI's open-weight speech recognition model and the strongest open option for production STT. On Common Voice benchmarks for Turkish, it lands around a 12 to 13 percent word error rate, a meaningful 10 to 20 percent improvement over Whisper v2. It supports 99 languages out of the box, and fine-tuned variants are widely available for languages where local phonetics need extra attention.
For real-time use, we run it behind a WebSocket service on the GPU node. End-to-end transcription latency on a DGX Spark sits in the 50 to 200 millisecond range per utterance, which is well inside the budget for natural conversation.
Text-to-Speech with Coqui XTTS-v2
Coqui XTTS-v2 supports 17 languages natively, including English, Spanish, French, German, Italian, Portuguese, Polish, Turkish, Russian, Dutch, Czech, Arabic, Mandarin, Hungarian, Korean, Japanese, and Hindi. It also supports voice cloning from a short reference WAV, which is how we give each deployment a consistent brand voice without contracting a voice actor.
On a GPU, XTTS-v2 produces a full sentence of natural speech in roughly 900 milliseconds to 1.5 seconds. We stream the output in roughly 50 millisecond chunks back over WebSocket, so the user starts hearing the response well before the full sentence has been synthesized. Sample rate is 22050 Hz, which is more than sufficient for a clean conversational voice.
LLM Reasoning with Llama 3.1 8B Instruct
Llama 3.1 8B Instruct is the reasoning core. It is small enough to share a GPU with Whisper and XTTS, multilingual enough to handle non-English conversation without falling back to English, and good enough at instruction-following to drive a real assistant. Turkish-tuned variants such as Cere-Llama-3-8B have been shown to beat the 70B base on grammar and history QA, which underlines how much headroom the 8B class has for language-specific work.
We serve it through an OpenAI-compatible API on the same edge node, which keeps the orchestration layer simple and lets us swap the model later without changing client code. For more on right-sizing models for edge use, our note on fine-tuned small language models covers when an 8B class model is the correct call.
Inside the Architecture: WebRTC, WebSocket, and Pipecat
The architecture splits cleanly into three layers. The browser captures audio over WebRTC. A lightweight FastAPI plus Pipecat server handles signaling and orchestrates the STT, LLM, and TTS calls. The heavy models run on the edge GPU node and expose Socket.IO WebSocket endpoints that the orchestrator drives.
The orchestrator's job is small but critical. It runs voice activity detection, segments user audio when they stop speaking, sends each segment to Whisper, hands the transcript to Llama 3.1, then forwards the LLM response to Coqui XTTS, and streams the resulting audio chunks back to the browser in roughly 50 millisecond pieces. Persistent WebSocket connections with auto-reconnect keep the per-request overhead negligible.
The split has three practical benefits. First, the orchestrator stays small enough to scale horizontally on commodity hardware. Second, the GPU node serves multiple concurrent voice agents without duplicating model load. Third, swapping any of STT, LLM, or TTS becomes a config change rather than a rewrite.
Latency Profile and Real-Time Performance
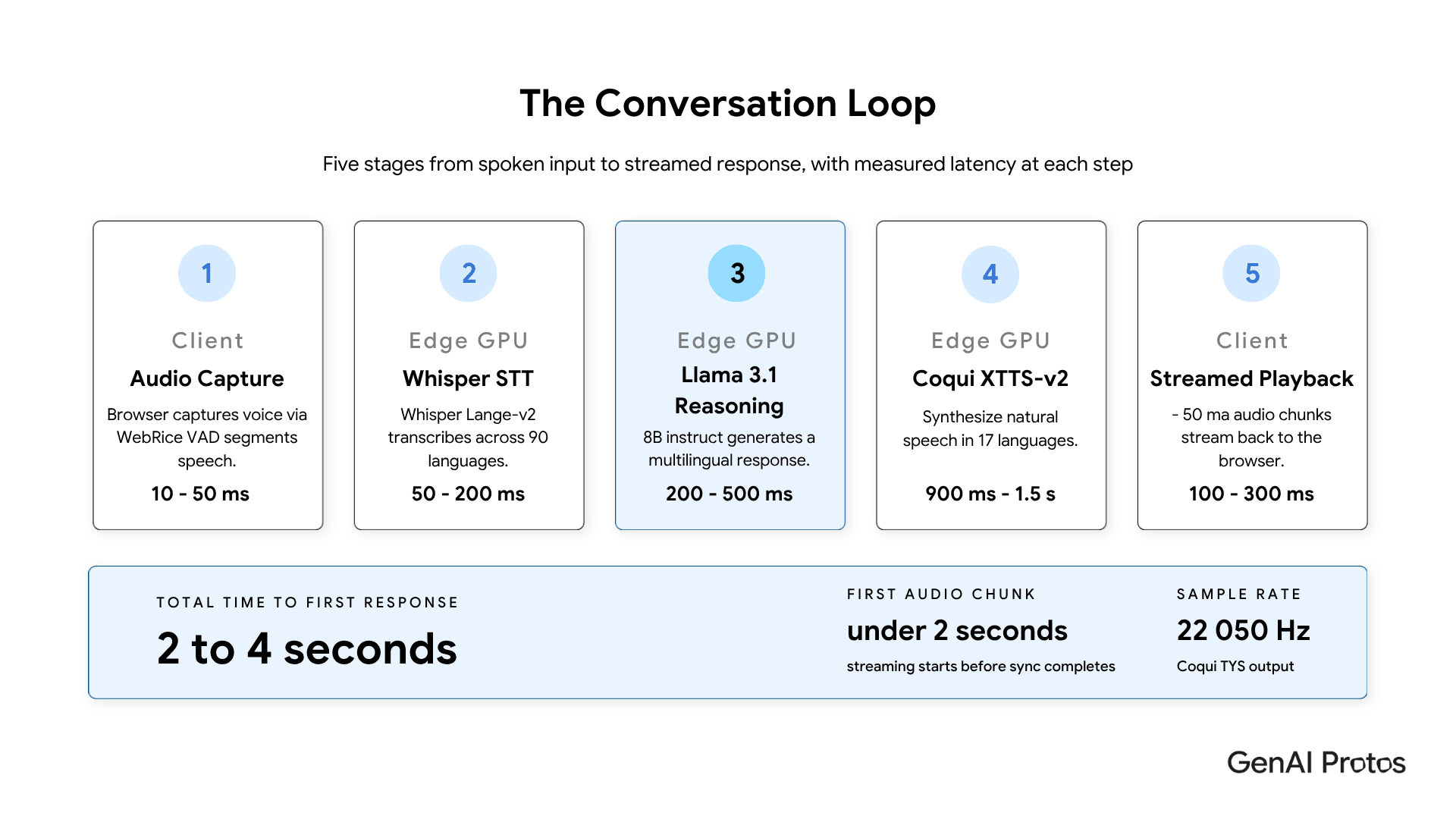
A local voice agent on a modern GPU node hits roughly 2 to 4 seconds for the first audible word of a response, with audio streaming starting much earlier than the total budget suggests. That is comparable to or better than most cloud voice stacks once network round trips are added back in.
The breakdown in production looks like this:
| Component | Latency | Notes |
| WebRTC audio capture | 10 to 50 ms | Depends on VAD threshold |
| Whisper Large-v3 STT | 50 to 200 ms | GPU accelerated |
| Llama 3.1 8B reasoning | 200 to 500 ms | Fits in 8B class budget |
| Coqui XTTS-v2 synthesis | 900 ms to 1.5 s | First sentence on GPU |
| Audio streaming | 100 to 300 ms | WebSocket plus chunking |
| Total to first response | ~2 to 4 s | First chunk arrives sooner |
Case Study: Turkish Voice Agent for a European Logistics Operator
A European logistics operator with field teams across Turkey and the broader EMEA region needed a Turkish-first voice assistant for warehouse and dispatch workflows. The constraint was strict. Audio could not leave the on-site network because of customer contract clauses, and the existing cloud voice pipeline was costing roughly 11,400 euros per month at current call volumes.
We deployed a local voice agent on a single DGX Spark node running Whisper Large-v3 for Turkish STT, Coqui XTTS-v2 with a cloned brand voice for TTS, and Llama 3.1 8B Instruct for reasoning, all behind a Pipecat orchestrator and a React WebRTC client. The full stack ran inside the operator's own VPC.
The measured results after the first quarter of production use were a 12.4 percent Turkish word error rate, which matched the cloud baseline, a median time to first audio of 1.6 seconds, and a 100 percent reduction in per-minute voice API spend. The operator redirected the savings into a second voice agent for German and Italian dispatch workflows on the same hardware. The counterfactual is the part the team flagged most often in the review. Without the local stack, they would have either accepted the contractual risk or carved out a smaller, English-only deployment that did not solve the actual problem.
The trade-off worth naming is voice cloning quality. The first XTTS voice we cloned for the brand was clearly synthetic in early A/B tests. We re-recorded the reference WAV with a longer, more varied script and the second clone passed user testing without comments.
Go deeper on private AI at the edge. Read our architectural guide on running production AI on local hardware, from model selection to deployment patterns:
Local Voice Agent vs Cloud Voice API
Choose a local voice agent when data residency, predictable cost, or offline operation are non-negotiable. Cloud voice APIs are still the right call for low-volume prototypes or consumer products where regulatory exposure is light and engineering capacity is the bigger constraint. The table below summarizes the trade-offs that decide where regulated teams land.
| Dimension | Local Voice Agent | Cloud Voice API |
| Data residency | Audio, transcripts, and responses stay on-prem | Raw audio sent to a third party and often logged |
| Cost model | Fixed hardware spend, no per-minute fees | Per-minute STT, LLM, and TTS billing that scales with traffic |
| Network dependency | Works on closed and air-gapped networks | Requires reliable internet on every call |
| Voice and language control | 17 languages on XTTS-v2 plus brand voice cloning | Limited voice options, brand voice usually a paid add-on |
| Latency | ~2 to 4 s to first response, first chunk under 2 s | Variable, network round trips on every call |
| Time to start | GPU node provisioning required | Ready in minutes with an API key |
| Best fit | Regulated industries, high-volume traffic, edge deployments | Low-risk prototypes, consumer apps, light traffic |
A short decision frame we use with clients: if audio contains PHI, PII at scale, or contractually restricted content, default to local. If monthly voice API spend is above five figures and traffic is steady, the business case for local often closes on cost alone. If the deployment has to work in a closed network, an air-gapped facility, or an unreliable link, local is the only viable answer. For teams working through this calculus across the broader stack, our piece on sovereign AI infrastructure covers the same trade-off applied to data and training, not just inference.
Key Takeaways
- A fully local voice agent keeps every part of the conversation, audio, transcript, response, on hardware you control, which is the cleanest answer to data residency and audit questions.
- Whisper Large-v3 plus Coqui XTTS-v2 plus Llama 3.1 8B Instruct fits on a single GPU appliance and matches cloud quality for English and 16 other languages including Turkish, German, Hindi, and Mandarin.
- A clean WebRTC, WebSocket, and Pipecat split gives you a lightweight orchestrator and a heavy model node, which scales independently and lets you swap any service later.
- Real production latency lands in the 2 to 4 second range to first response, with streamed audio starting well before that, which reads as natural conversation.
- The cost case is often decisive on its own. Steady voice traffic at five-figure monthly cloud spend pays back local hardware quickly.
- Voice cloning needs careful reference audio. Plan for a second pass on the brand voice if the first clone does not pass A/B testing.
Conclusion
A fully local voice agent is no longer a research project. With Whisper Large-v3, Coqui XTTS-v2, and Llama 3.1 8B on a single GPU appliance, plus a clean WebRTC and WebSocket pipeline, you can ship a multilingual, brand-consistent voice assistant that meets enterprise privacy requirements and outperforms the cost profile of a comparable cloud stack. The hardest design choices are no longer about whether the local approach works. They are about how to right-size the GPU node, which languages to prioritize, and how to handle the operational reality of running inference in your own environment. For most regulated teams, that is a much better problem to have than the one cloud voice APIs leave them with.
