Introduction
Your vector search works. It returns relevant chunks. It powers a decent chatbot. Then a compliance officer asks one question: “Can you prove this answer respects our policy on cross-border data sharing?” Or a clinician asks: “Why did the model recommend this drug, given the patient’s existing prescriptions and known interactions?” Or a credit analyst asks: “Show me every entity connected to this counterparty within two hops of a sanctioned party.”
Vector search shrugs. It does not know what an entity is. It does not know what a policy is. It does not know what “two hops” means. It only knows that one chunk of text was numerically close to another.
This is the moment most regulated-industry AI programs hit a wall. The fix is not a better embedding model or a smarter reranker. The fix is a knowledge graph, often layered with vector search in a pattern now widely called GraphRAG. This post is the practical decision guide for when to reach for one, when to stay with vectors, and how to combine the two without rebuilding everything you already shipped.
What a Knowledge Graph Actually Adds
Quick answer: A knowledge graph is a structured representation of entities (people, drugs, accounts, contracts, regulations) and the typed relationships between them. It adds three things a vector database cannot: explicit relationships you can traverse, business rules you can enforce, and a query layer that produces explainable, auditable results. In regulated AI, those three things are not nice-to-haves. They are the system.
A vector database finds text that looks like other text. That is enough for “summarize this document” or “find similar policies.” It is not enough for “list every drug interaction for this patient given their current medications, allergies, and renal function, excluding off-label uses not approved in the EU.” That sentence is not a similarity question. It is a graph traversal with constraints.
Knowledge graphs are how enterprise AI moves from “the right chunk” to “the right answer under the right rules.” That is the difference between a tool the legal team tolerates and a tool the legal team will sign off on.
The three capabilities you cannot replicate with vectors alone
A knowledge graph gives you typed relationships (drug X interacts_with drug Y; counterparty A is_subsidiary_of counterparty B), constraint logic (this patient is_allergic_to this compound; this account exceeds this exposure threshold), and provenance (every edge can carry source, date, and confidence). Vector search has none of these natively. You can fake some of them with metadata filters, but you hit the ceiling fast in any domain with more than a handful of entity types.
A vector database answers “what is this similar to.” A knowledge graph answers “what does this connect to, under what rules, and how do I prove it.”
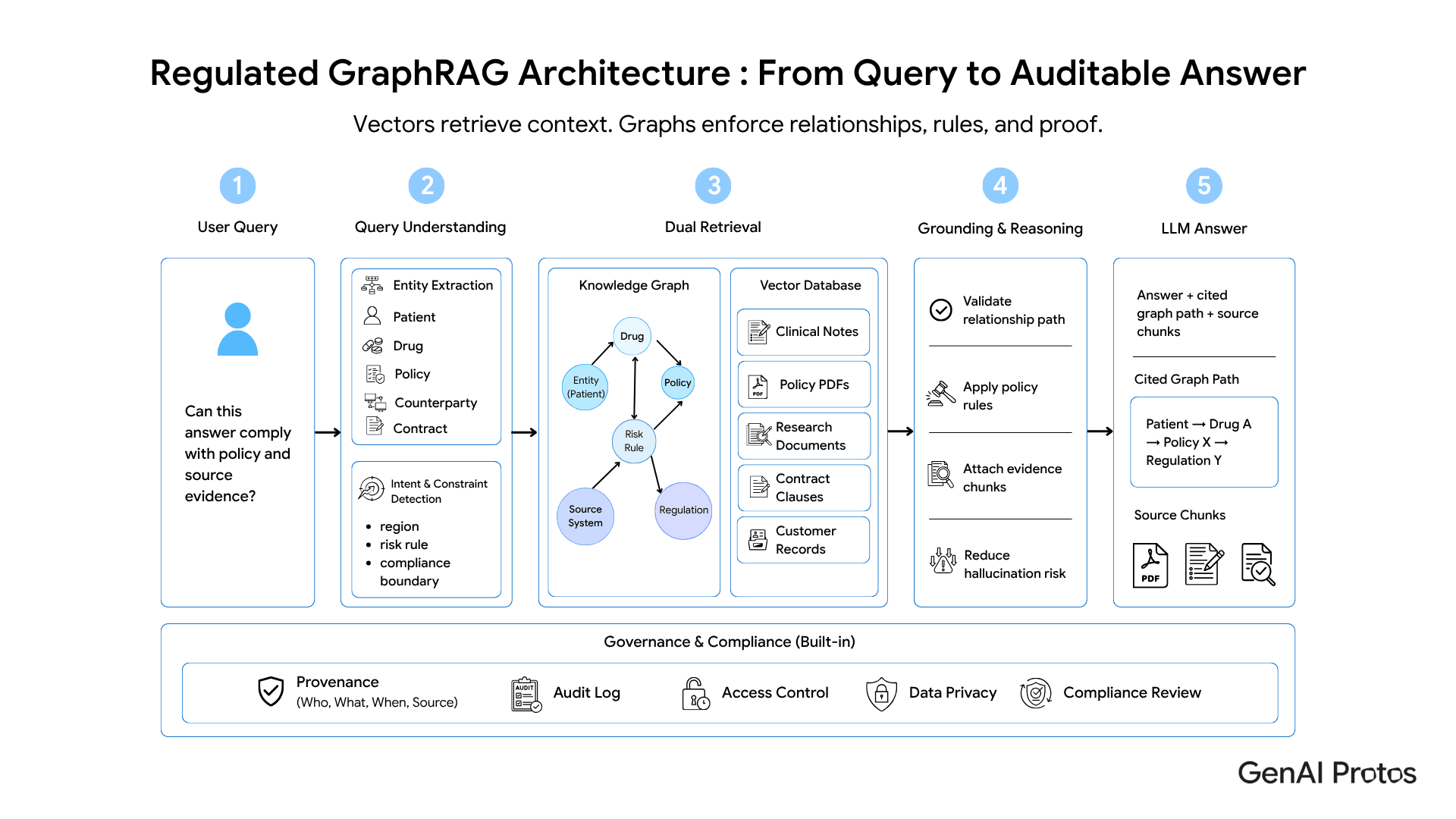
How GraphRAG Works in a Regulated Environment
Quick answer: GraphRAG is the production pattern where a knowledge graph and a vector index are queried together. The graph supplies entity relationships, policy edges, and exact constraints. The vector store supplies unstructured context like clinical notes, contract clauses, or research papers. The LLM stitches both into an answer it can explain. This combination is what makes the system both accurate and defensible.
The pattern looks like this. A user query is parsed for entities and intent. Those entities seed a graph traversal that pulls relationships, rules, and structured facts. In parallel, the same query hits a vector index to pull unstructured context. Both result sets are passed to the LLM, often with explicit instructions to cite the graph paths it used. The model now has both the “what” and the “why.” So does the auditor.
Step 1 - Extract entities, not just embeddings
The first step in any GraphRAG system is entity recognition tuned to your domain. A generic NER model will miss the entities that matter most in healthcare (drug doses, ICD codes, lab values) or finance (LEIs, instrument identifiers, regulatory entities). Domain-tuned extraction is what makes the graph useful. Skip this and you end up with a graph full of strings that should have been linked entities.
Step 2 - Build the graph from sources you can defend
Edges in a knowledge graph must carry provenance. Every relationship needs to point to the document, regulation, or system of record that produced it. This is non-negotiable in regulated domains. When the auditor asks where the “interacts_with” edge came from, the answer cannot be “the LLM said so.” It has to be “FDA label, version, retrieved on date.”
Step 3 - Query the graph and the vector store in parallel
Production GraphRAG runs both retrieval paths concurrently and merges results before generation. The graph path returns structured facts and the traversal that produced them. The vector path returns unstructured context. The LLM is prompted to ground its answer in the graph facts first, then expand with the vector context. This ordering is the difference between a system that hallucinates compliantly and one that does not hallucinate at all.
Step 4 - Make the answer auditable by default
Every answer should carry the graph paths it used and the vector chunks it cited. This is the EEAT signal regulators actually care about. It is also the difference between a tool that ships and a tool that gets stuck in legal review for six months.
In regulated AI, an answer without a citation chain is not an answer. It is a liability.
Related example: Advanced PDF Analysis and Conversational Agent shows how conversational document analysis can support source-grounded retrieval across enterprise files.
Already exploring GraphRAG or knowledge graph patterns for enterprise AI? GenAI Protos builds RAG and knowledge-grounded systems for regulated industries. See our RAG Applications expertise
Vector DB vs Knowledge Graph vs Hybrid (GraphRAG)
Quick answer: Vector databases win on unstructured search and speed of deployment. Knowledge graphs win on relationships, rules, and explainability. GraphRAG wins on regulated workflows that need both. The decision is not “which is better.” It is “which job am I doing.” Most enterprise AI programs in regulated industries end up needing all three layers eventually.
Decision Comparison
| Criteria | Vector DB only | Knowledge Graph only | GraphRAG (hybrid) |
|---|---|---|---|
| Best for | Semantic search, summarization, Q&A over text | Relationship queries, rule enforcement, compliance | Regulated AI that needs context plus constraints |
| Handles unstructured text | Excellent | Poor on its own | Excellent |
| Handles multi-hop relationships | Poor | Excellent | Excellent |
| Enforces business rules and policies | Very limited | Native | Native |
| Explainability and citation | Chunk-level only | Path-level and entity-level | Both |
| Setup effort | Low | High | Highest |
| Maintenance burden | Low | High (schema evolution) | High |
| Time to first value | Days to weeks | Months | Months |
| Best fit examples | Customer support search, doc Q&A | Drug interaction checking, KYC, AML | Clinical decision support, compliant claims, AML investigations |
The decision framework in one paragraph
If your queries are “find me text that talks about X,” a vector DB is enough. If your queries are “tell me how X connects to Y under rule Z,” you need a knowledge graph. If your queries are both, in a regulated context where every answer must be traceable, you are in GraphRAG territory. Most enterprise AI roadmaps in healthcare, finance, and pharma end at GraphRAG. They just take a year longer than they should because teams over-invest in vectors before discovering the wall.
Vector DBs are how you start. Knowledge graphs are how you scale into regulated production. GraphRAG is how you ship both.
Related example: Chat with Google Drive for Legal Services demonstrates advanced search over enterprise document repositories where grounding and source access matter.
Want a deeper comparison of MCP, RAG, and AI agents across enterprise architectures? Our deep dive lays out the trade-offs and shows where each pattern fits. Read MCP vs RAG vs AI Agents
Three Scenarios Where Vector Search Falls Short
Quick answer: Vector search hits a hard ceiling in three scenarios that show up constantly in regulated enterprise AI: multi-hop entity reasoning, policy and rule enforcement, and explainable answers for audit. In each, a knowledge graph (alone or as GraphRAG) is the lift that turns the system from “useful demo” into “production tool the compliance team approves.”
Scenario 1-Multi-hop entity reasoning (finance, pharma, legal)
The question: “Which of our counterparties is connected, within three hops, to a sanctioned party through ownership, directorship, or shared address?” A vector search returns documents mentioning sanctions. It does not traverse the ownership graph. It cannot. A knowledge graph can. This is the AML and KYC pattern almost every Tier 1 bank now runs through a graph layer, and it is the pattern most fintechs underestimate until their first regulatory review. For external context, see Neo4j’s documentation on graph data science for fraud detection.
Scenario 2-Policy and rule enforcement (healthcare, insurance)
The question: “Should this prescription be flagged given the patient’s allergies, current medications, kidney function, and the regional formulary?” The answer is not in a paragraph somewhere. The answer is the result of evaluating constraints across multiple entity types. A graph encodes those constraints once and applies them everywhere. A vector store cannot. This is why clinical decision support and prior authorization workflows almost always sit on top of a graph, even when the surrounding system is RAG-shaped.
Scenario 3-Auditable explanations for regulators (every regulated industry)
The question: “Why did the system give this answer, and can we reproduce the reasoning?” Vector retrieval can cite chunks. It cannot reconstruct a reasoning path. A knowledge graph can. Every edge has provenance. Every traversal can be logged. Every answer can carry a citation chain a regulator can verify. This is the EEAT and audit dimension that ultimately decides whether a regulated AI system goes live or gets shelved. See our writeup on private AI for regulated industries for the broader architectural picture.

Section 5: Where Knowledge Graphs Fail and What Teams Get Wrong
Quick answer: Knowledge graphs are powerful and expensive. They fail when teams treat them as a database project instead of a product, build the schema without input from the domain experts who will query it, or try to put everything in the graph instead of only what needs to be related. The honest trade-off is real upfront effort for compounding downstream value, and you should not start unless you have a use case that justifies it.
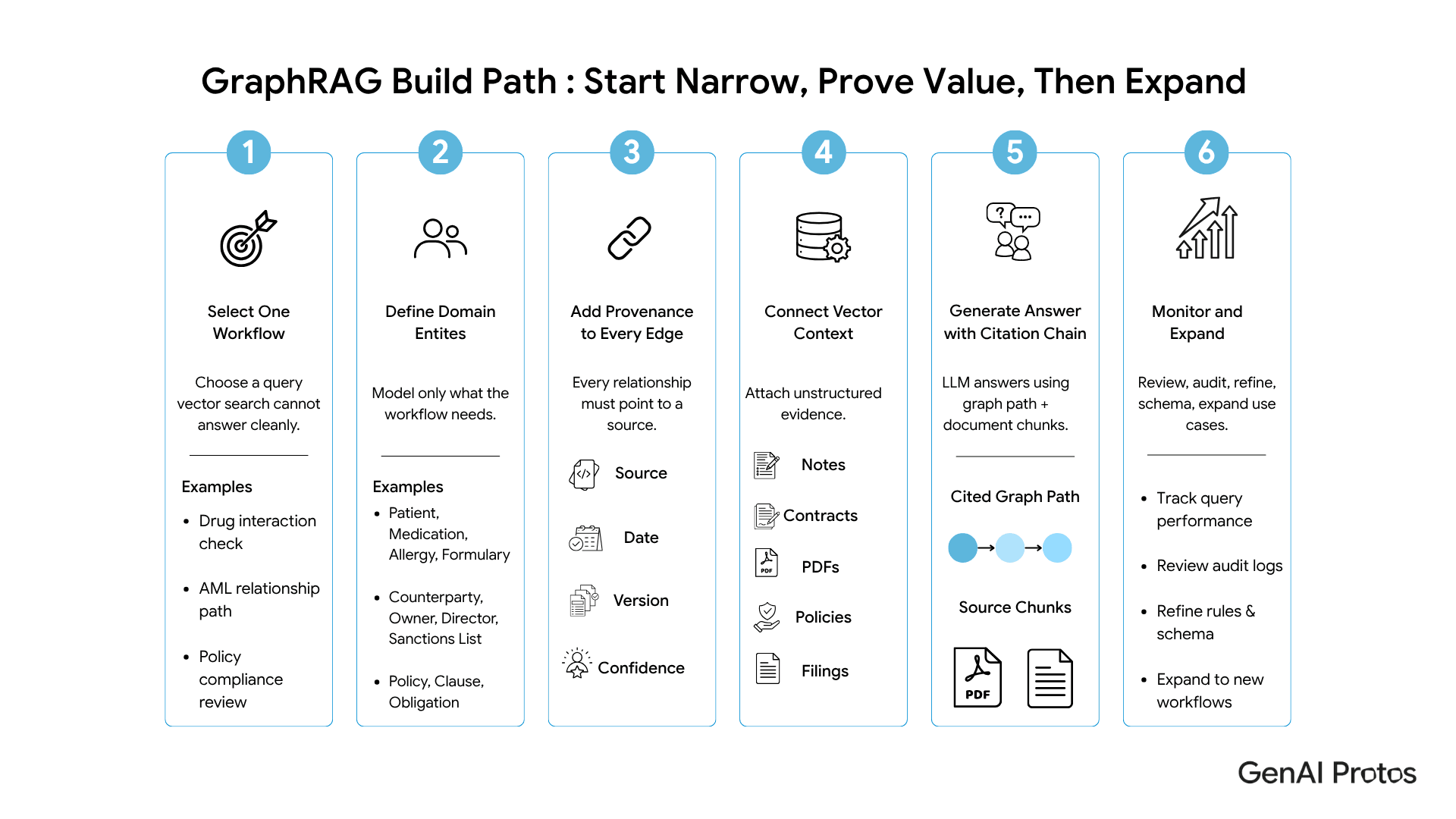
Common pitfall: Modeling every entity in the enterprise before shipping anything.
What to do instead: Pick one workflow that vector search cannot answer cleanly. Model only the entities and relationships that workflow needs. Ship. Expand.
Common pitfall: Treating the graph schema as an IT artifact.
What to do instead: The schema is a product. It must be owned by domain experts (clinicians, analysts, compliance leads). If your schema review meeting does not include them, the graph will not be trusted by the people who need to use it.
Common pitfall: Building the graph from LLM extractions without provenance.
What to do instead: Every edge needs a source, a date, and an extraction method. LLM-extracted edges are fine as long as they carry that metadata and can be reviewed. Edges without provenance are technical debt that becomes regulatory risk.
Common pitfall: Choosing a graph database before defining the queries.
What to do instead: Sketch the actual queries first. Property graphs (Neo4j, Memgraph) optimize for traversal. RDF and SPARQL stacks optimize for semantic reasoning and federated data. The right choice depends on your queries, not the vendor pitch.
The trade-off is straightforward. Knowledge graphs cost more to build and more to maintain than a vector store. In return, they unlock workflows vector search cannot. If your compliance, clinical, or financial workflow needs relationships and rules, the cost is justified. If it does not, you do not need a graph and you should not build one to look modern. This is true even with GraphRAG and the current wave of tooling around it.
The most expensive knowledge graph is the one you built before you knew what to ask it.
Key Takeaways
- Vector databases handle similarity. Knowledge graphs handle relationships, rules, and explainability. In regulated AI you almost always need both, layered as GraphRAG.
- The decision is not vector versus graph. It is which job you are doing, and most enterprise programs in healthcare, finance, and pharma eventually need the graph layer.
- A knowledge graph is only as defensible as the provenance on its edges. Every relationship must point to a verifiable source.
- Start with one workflow vector search cannot answer cleanly. Model the entities and relationships that workflow needs. Expand only after the first one ships.
- GraphRAG is the production pattern for regulated industries: graph for facts and rules, vectors for context, LLM for synthesis, citations for audit.
Conclusion
Enterprise GraphRAG matters when vector search cannot explain relationships, enforce rules, or produce an audit-ready reasoning path. In regulated domains, the system must show how an answer was grounded, not just return relevant chunks.
The practical route is to start with one workflow, model only the required entities and relationships, add provenance to every edge, and expand once the first defensible workflow proves value.



