Why "Just Use the API" Is No Longer Enough for Enterprise AI
When enterprise teams first started experimenting with large language models, the path was obvious. Sign up for an API key, connect your application, and start getting results in days. OpenAI, Anthropic, Google all of them offered powerful models accessible over HTTPS. For prototypes and internal experiments, that approach worked well.
The problem is that enterprise AI has moved beyond experiments.
Today, AI systems are being embedded into customer support workflows, legal document review, financial analysis, clinical documentation, and HR operations. Every one of these workflows touches data that is sensitive, regulated, or both. Every prompt sent to a public API carries the risk however small that sensitive information leaves your infrastructure.
That risk has changed how enterprises think about AI deployment.
A healthcare organisation cannot send patient records to a third-party API and remain HIPAA compliant. A law firm cannot route privileged client documents through a public cloud endpoint. A financial institution operating under EU regulations cannot process customer transaction data on infrastructure it does not control. For these organisations, private LLM deployment is not a preference. It is a requirement.
And the numbers reflect it. According to a 2026 enterprise AI survey, 72% of mid-to-large enterprises now say data privacy and compliance are their top concerns when deploying AI in production up from 41% in 2024. The shift is structural, not temporary.
Private LLM deployment for enterprises has moved from a niche infrastructure choice to the mainstream architecture decision for any organisation that takes data governance seriously.
What Is Private LLM Deployment?
Private LLM deployment means running a large language model on infrastructure that you control rather than sending requests to a shared, third-party API. The model processes your data inside your environment. Nothing leaves without your explicit authorisation.
In simple terms: instead of calling OpenAI's server to run your prompt, the model runs on your server.
This can mean different things depending on your infrastructure setup:
- On-premise: the model runs on hardware you own and operate, inside your own data centre or office environment
- Private cloud (VPC): the model runs in a dedicated, isolated cloud environment your own virtual private cloud on AWS, Azure, or Google Cloud where your data does not mix with other tenants
- Hybrid: some AI workloads run on-premise, others run in a private cloud environment, with a governed boundary between them
What all three share is the same core principle: your data stays under your control at every point in the pipeline.
This is different from simply using a cloud AI service like Azure OpenAI or AWS Bedrock. Those services offer guardrails and data processing agreements, but they still run on shared infrastructure managed by a third party. Private AI deployment means the compute, the model weights, and the data pipeline all sit within an environment you own and govern.
Enterprise Private LLM Architecture - How the Three Models Connect
Before diving into each model separately, this diagram shows how all three deployment options fit into a single enterprise architecture view.
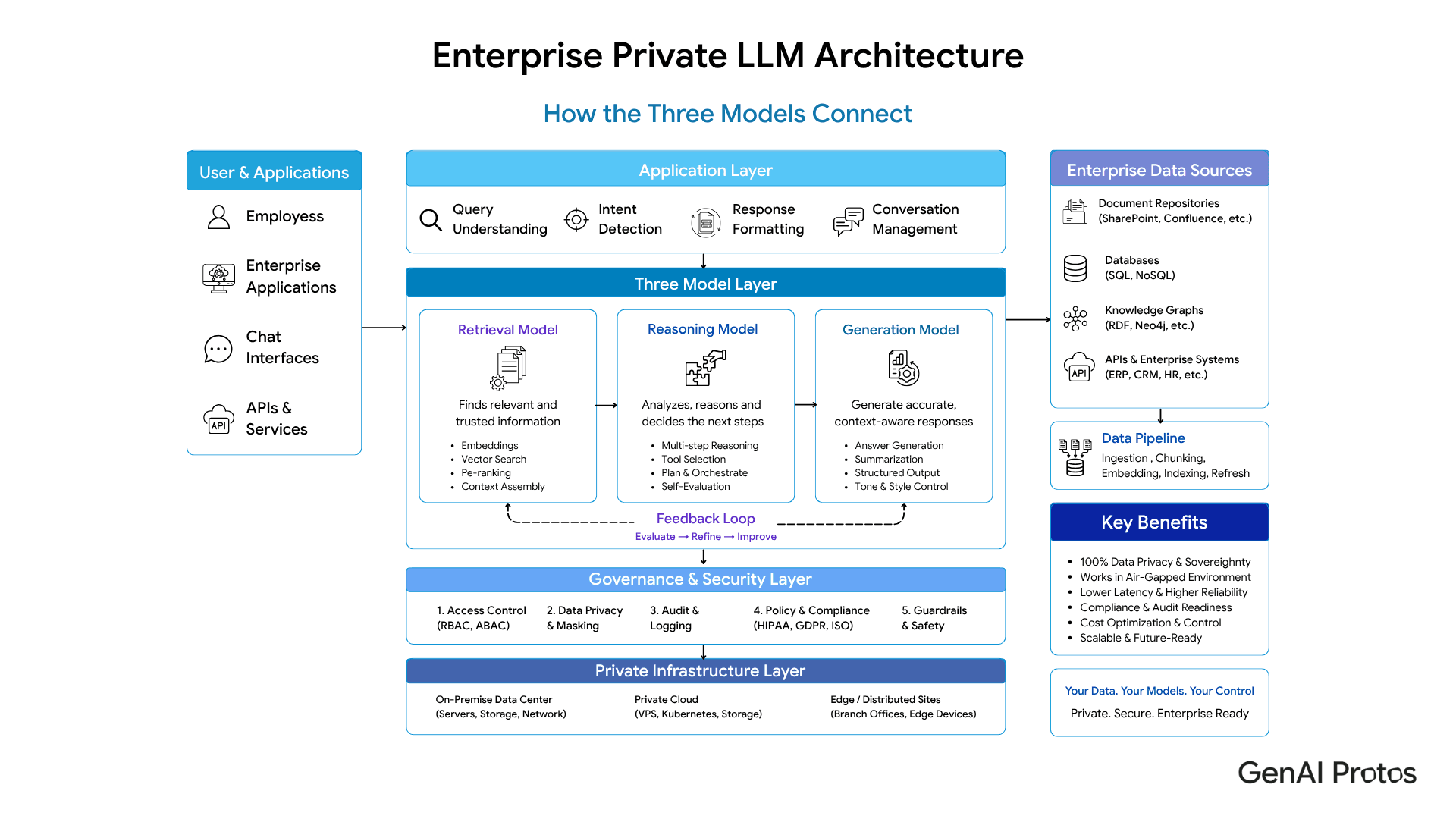
The 3 Private LLM Deployment Models Explained
Before choosing a deployment model, it helps to understand what each one involves in practice not just in theory.
On-Premises LLM Deployment
On-premises means the model runs on hardware you physically own and operate. This could be a GPU server in your data centre, a high-performance workstation in a secure lab, or an edge device like an NVIDIA Jetson or DGX Spark deployed at a specific facility.
The defining feature of on-premise LLM deployment is that no data ever travels outside your physical environment. The model processes everything locally, the outputs stay local, and there is no dependency on an internet connection for inference.
This is the architecture of choice for organizations that require full air-gapping — where even a private cloud environment is not secure enough because the data cannot leave a specific physical location under any circumstances.
On-premise LLM deployment works best for:
- Government and defence environments with strict data residency rules
- Hospitals and clinical facilities where patient data must never leave the building
- Financial institutions operating under regulations that require on-site data processing
- Industrial environments where AI needs to run without any network connectivity
The trade-off: On-premise is the most expensive and most operationally demanding deployment model. Your team is responsible for hardware procurement, model serving, updates, scaling, and maintenance. There is no elasticity if your usage spikes, you absorb it with the hardware you already have.
Private Cloud LLM Deployment (VPC)
Private cloud deployment means running your LLM inside a dedicated, isolated cloud environment a Virtual Private Cloud (VPC) provisioned exclusively for your organisation. Your data does not share compute or storage with any other tenant.
This model gives you the data isolation benefits of on-premise without the hardware overhead. The cloud provider manages the physical infrastructure. You manage the model, the data, and the access controls inside your dedicated environment.
Private cloud LLM deployment works best for:
- Enterprises that need compliance-grade data isolation but do not want to manage physical hardware
- Teams that need to scale AI compute up and down based on actual usage
- Organisations operating across multiple geographies that need consistent AI infrastructure without building data centers in each location
- Businesses that want the flexibility to swap models as better open-source options become available
The trade-off: You still depend on a cloud provider for the underlying infrastructure. If your regulatory framework requires that data never touch third-party infrastructure even dedicated, isolated infrastructure private cloud does not satisfy that requirement. On-premise does.
Hybrid LLM Deployment
Hybrid LLM architecture splits AI workloads intelligently between on-premise and private cloud infrastructure based on data sensitivity, latency requirements, and cost.
A common pattern: sensitive customer data is processed entirely on-premise. General knowledge tasks, anonymised queries, and non-regulated workloads are processed in a private cloud environment where compute is cheaper and more elastic. A governance layer manages the boundary between the two environments and enforces which data can travel where.
Hybrid LLM architecture works best for:
- Large enterprises with a mix of regulated and non-regulated AI workloads
- Organisations that want the security of on-premise for sensitive workflows while keeping costs manageable for general AI tasks
- Teams migrating from cloud-first AI toward private infrastructure using hybrid as a transition architecture
- Businesses operating in multiple jurisdictions with different data residency requirements
The trade-off: Hybrid is the most complex of the three models to design, govern, and operate. Getting the boundary between environments right and keeping it right as workloads evolve requires careful architecture and ongoing governance. Done well, it is the most cost-efficient option at scale. Done poorly, it creates the compliance gaps it was supposed to prevent.
Enterprise Deployment Cost Comparison
One of the most important and most frequently skipped parts of any private LLM deployment decision is the cost picture. Not just the setup cost, but the full operational cost over 12 and 24 months.
| Factor | On-Premise | Private Cloud (VPC) | Hybrid |
|---|---|---|---|
| Initial cost | High (hardware procurement, setup) | Low (no hardware to buy) | Medium (hardware for sensitive workloads only) |
| Monthly running cost | Low (after setup, no per-token billing) | Medium (compute costs scale with usage) | Medium (mix of fixed + variable) |
| Cost at scale | Most cost-efficient long-term | Costs grow with usage volume | Efficient if workload split is well-designed |
| Compliance cost | Lowest (all controls in-house) | Medium (audit + VPC governance) | Medium (dual environment governance) |
| Scalability | Limited by hardware you own | High - elastic compute | High - scale cloud side, fixed on-prem side |
| Operational overhead | Highest (your team manages everything) | Low to medium (cloud manages infrastructure) | Highest (two environments to govern) |
| Best cost scenario | High volume, regulated, stable workloads | Variable workloads, no air-gap needed | Large enterprise, mixed data sensitivity |
The honest cost summary: On-premise has the highest upfront cost but the lowest long-term running cost at scale it is the most economical option for high-volume, stable workloads. Private cloud VPC has low entry cost but ongoing compute bills that grow with usage. Hybrid is the most complex to price accurately but can be the most efficient when the workload split is correctly designed from the start.
Private LLM vs Cloud LLM: Key Differences
Understanding the difference between private LLM deployment and standard cloud LLM API usage is the foundation for any enterprise deployment decision.
The honest takeaway: public cloud APIs are better for speed and simplicity. Private LLM deployment is better for control, compliance, and long-term cost at scale. The right choice depends on what your actual constraints are and which constraints are non-negotiable.
How to Choose the Right Deployment Model - Decision Tree
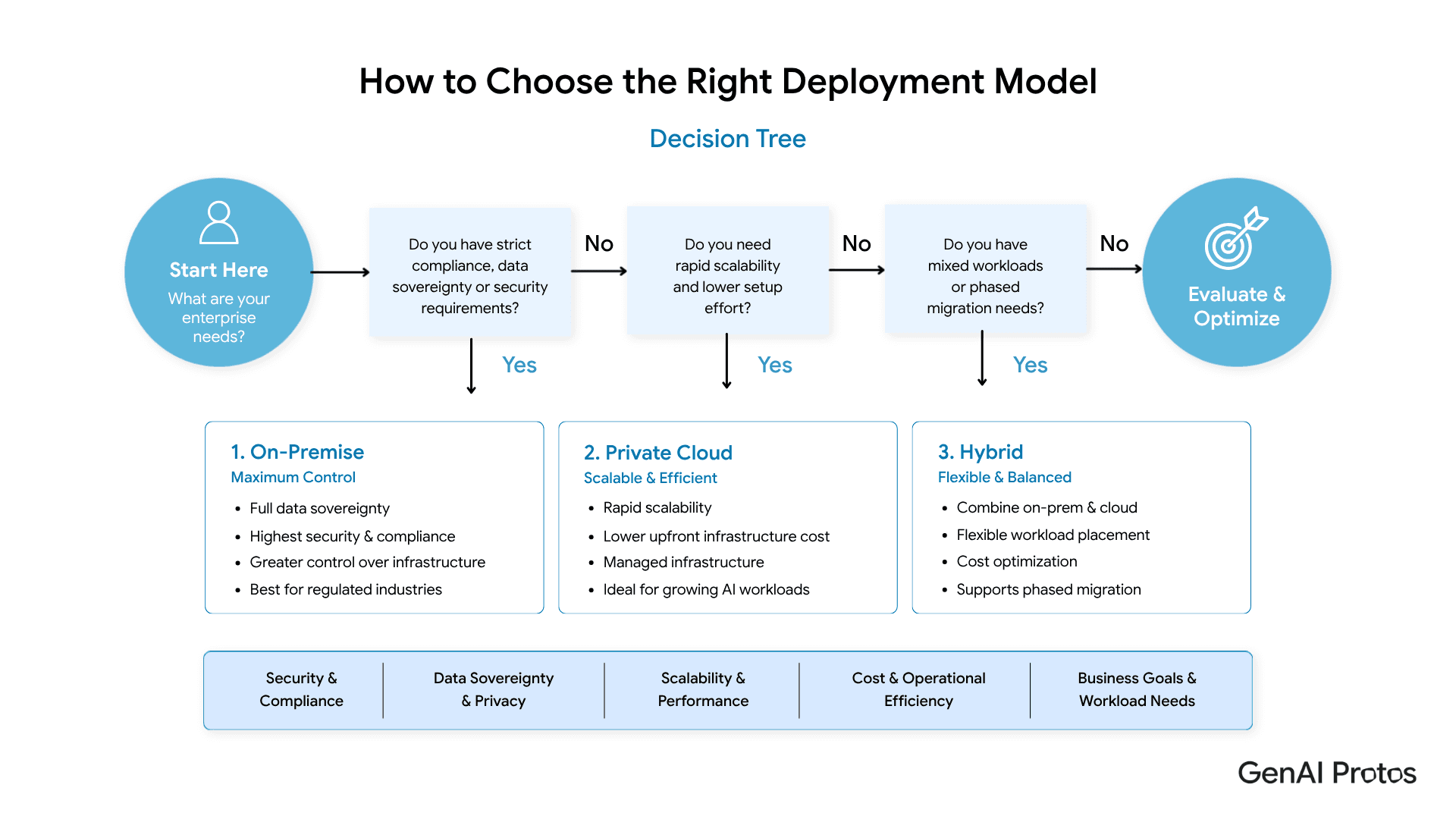
Use this decision tree before evaluating vendors, hardware, or frameworks. The right architecture follows from your constraints not from what is easiest to sell.
How to Choose the Right Private LLM Deployment Model: Decision Framework
Most enterprise teams overthink this decision at the start and underthink it at the wrong moments. Here is a clear three-step framework.
Step 1 - Identify Your Non-Negotiable Constraints
Before you evaluate any architecture, list the things that cannot be compromised.
Regulatory requirements: Does your industry require data to stay within specific geographic boundaries? Does your compliance framework (HIPAA, GDPR, FCA, EU AI Act, ISO 42001) restrict where data can be processed? If yes, on-premise or private VPC is your starting point not an option.
Data sensitivity: Does your AI system process personal data, financial records, clinical information, or legally privileged communications? If yes, public cloud APIs introduce risk that your legal and compliance teams will likely not accept in a production deployment.
Connectivity requirements: Does your AI system need to operate without internet access on a factory floor, in a clinical setting, or in a secure government facility? If yes, on-premise is the only option.
Step 2 - Assess Your Operational Capacity
Private LLM deployment requires infrastructure to run on. The question is whether your team has the capacity to build and maintain that infrastructure.
Key questions to answer honestly:
- Do you have ML engineers who have deployed model serving infrastructure (vLLM, Ollama, TGI)?
- Do you have the GPU hardware budget or cloud budget for a dedicated VPC to host models at your required throughput?
- Do you have an internal team for model updates, security patching, and performance monitoring?
If the answer to all three is no, the architecture choice matters less than the implementation partner you choose. A well-deployed private cloud VPC maintained by an experienced partner will outperform a poorly deployed on-premise system every time.
Step 3 - Match Architecture to Use Case
Once you know your constraints and capacity, the architecture choice usually becomes clear:
- High sensitivity +air-gap required + hardware budget: On-premise
- High sensitivity + noair-gap required + need for elasticity: Private cloud VPC
- Mixed sensitivity workloads + largeorganisation: Hybrid
- Low sensitivity + speed to market is the priority: Private cloud VPC with data processing agreements
When Should You Deploy a Private LLM?
Use private LLM deployment when:
- Your industry is regulated and requires documented data sovereignty (healthcare, financial services, legal, government)
- Your AI workflows process personal data under GDPR, HIPAA, or equivalent frameworks
- Your organisation has received guidance from legal or compliance teams about data leaving your infrastructure
- Your AI system needs to operate without internet connectivity at the edge, in manufacturing, or in a secure facility
- You are deploying AI at a scale where per-token API billing is becoming a significant budget line item
- You need to fine-tune or modify the underlying model which public APIs do not allow
Stay with a public cloud API when:
- You are still in the prototype or proof-of-concept stage and speed of iteration is the priority
- Your AI workloads do not touch sensitive, regulated, or personally identifiable data
- Your organisation does not yet have the ML infrastructure team to manage a private deployment
- Your usage volume is low and consistent where per-token billing is cheaper than maintaining dedicated infrastructure
How Enterprises Are Using Private LLMs in Production
Private AI deployment is not theoretical. These are production deployments with real business outcomes.
Healthcare - Clinical Documentation Without Cloud Dependency
A regional healthcare organisation deployed a private LLM deployment on NVIDIA Jetson hardware across clinical facilities. The system processes patient intake notes, generates visit summaries, and supports clinical decision workflows entirely on-premise, with zero data leaving the facility network.
The previous workflow required clinicians to spend 35–40% of their working day on documentation. Post-deployment, that dropped to under 15%. No cloud API. No HIPAA risk. No ongoing per-token cost that scales with volume.
Financial Services Regulatory Query Intelligence
A Tier-1 financial institution deployed a self-hosted LLM enterprise system in a private cloud VPC to handle internal regulatory compliance queries. Analysts can now ask natural-language questions about regulatory requirements, cross-referenced against internal policy documents, and receive cited answers in minutes rather than hours.
The critical requirement was that no client data or internal policy documentation could leave the firm's infrastructure. A private VPC deployment with a RAG layer over internal document repositories satisfied this requirement without sacrificing response quality.
Legal Services - Contract Analysis at Scale
A global law firm deployed an air-gapped LLM deployment for contract review workflows handling client-privileged documents. The system reviews, flags risk clauses, and generates executive summaries all within the firm's isolated infrastructure, with a full audit trail of every inference for professional liability compliance.
Processing time per contract dropped from 4–6 hours (manual review) to under 20 minutes. Lawyer review time is now focused on the flagged clauses and final judgements, not the initial read-through.
Manufacturing - Edge AI Without Internet Dependency
A manufacturing enterprise deployed private AI on NVIDIA Jetson devices at production facilities in geographies with unreliable internet connectivity. The on-device LLM handles maintenance query responses, operator guidance, and quality control flagging in real time, without any cloud dependency.
Downtime from maintenance delays dropped 28% in the first six months, because operators could get accurate, instant guidance without waiting for remote expert consultation.
Building a Production-Ready Private LLM Environment for Enterprises
This is where most enterprise teams underestimate the scope. The model is only one part of the deployment. Here is what you actually need to build a production-grade private LLM deployment.
Hardware selection. The right hardware depends on model size and throughput requirements. For edge deployments, NVIDIA Jetson Orin and DGX Spark are the leading options. For data centre deployments, NVIDIA A100 or H100 GPUs are the enterprise standard. Getting hardware sizing wrong is one of the most common and most expensive mistakes in enterprise AI infrastructure planning.
Model serving infrastructure. The model needs a serving layer that handles requests, manages GPU memory, batches concurrent queries for efficiency, and exposes an API that your applications can call. The leading open-source options in 2026 are vLLM (best for high-throughput, multi-GPU serving), Ollama (best for simpler deployments and developer setups), and Text Generation Inference (TGI) from Hugging Face (strong for production deployments with monitoring integrations).
Security and access control. A private LLM deployment without proper access controls is not private in any meaningful sense. Every endpoint needs authentication. Inference logs need to be captured and stored. Network access to the model serving layer needs to be restricted to authorised internal systems only.
Evaluation and monitoring. Once the model is running, you need to know whether it is running well. Output quality monitoring, latency tracking, error rate logging, and regular evaluation against a representative test set are all required for a production deployment your team can trust and improve over time.
Fine-tuning pipeline (ifrequired). If your use case requires domain-specific performance clinical terminology, legal language, financial product knowledge you will need a fine-tuning pipeline that can update the model as your internal knowledge evolves. This is not a one-time task. It is an ongoing operational process.
| Infrastructure Component | Options | Best For |
|---|---|---|
| Edge hardware | NVIDIA Jetson Orin, DGX Spark | Air-gapped, on-premise, edge deployments |
| Data centre GPU | NVIDIA A100, H100 | High-throughput enterprise deployments |
| Model serving | vLLM, Ollama, TGI | API layer for LLM inference |
| Base model | Llama 3.1, Mistral, Phi-4, Gemma 2 | Open-source, fine-tunable, commercial licence |
| RAG layer | LangChain, LlamaIndex, Agno | Private knowledge retrieval over enterprise data |
| Monitoring | LangSmith, Prometheus, Grafana | Inference quality, latency, error tracking |
| Fine-tuning | LoRA, QLoRA on local GPU | Domain-specific model adaptation |
How GenAI Protos Builds Private LLM Deployments for Enterprise
At GenAI Protos, private LLM deployment is not a configuration exercise. It is an engineering engagement that starts with understanding your data environment, your compliance requirements, and your operational constraints and works backward from there to the right architecture.
Our work covers the full deployment stack: hardware selection and sizing, model evaluation and selection, serving infrastructure, security and access controls, RAG layer design for private knowledge retrieval, fine-tuning pipelines for domain-specific performance, and ongoing monitoring and evaluation.
We have built private LLM deployments on NVIDIA Jetson hardware for clinical settings, in private cloud VPC environments for financial services, and in hybrid LLM architectures for large enterprises with mixed data sensitivity across their AI workload portfolio.
The difference between a private LLM deployment that delivers and one that stalls in a six-month pilot is almost always the quality of the infrastructure design and the clarity of the compliance architecture from day one. Getting those right at the start is significantly faster and cheaper than trying to fix them after the deployment is already running.
If your organisation is evaluating a move to private AI infrastructure or has started a deployment that is not performing as expected the underlying architecture, not the model, is almost certainly the place to start.
Conclusion: The Location of Your Model Is a Business Decision, Not Just a Technical One
Where your LLM runs determines what data it can access, who can audit its decisions, and whether your organisation can defend its AI deployments to regulators, clients, and board members.
Private LLM deployment for enterprises is the answer for organisations that have moved beyond experimentation and are deploying AI in workflows that touch real business data, real customers, and real compliance obligations. It is not the easiest starting point. But in 2026, for the class of enterprise AI deployments that are actually delivering business value, it is increasingly the only architecture that holds up under scrutiny.
The choice between on-premise, private cloud, and hybrid is secondary to the first decision: committing to an architecture where your data sovereignty and your data stay under your control. Once that decision is made, the rest of the design follows from your actual constraints not from the default path of least resistance.
