NVIDIA Powered voice based Agentic RAG
NVIDIA Powered voice based Agentic RAG
Cloud-native voice agentic RAG converts documents into interactive, source-grounded conversations using AI, vectors, and speech.
NVIDIA Agentic RAG Solution | GenAI Protos
Build agentic RAG pipelines powered by NVIDIA for enterprise AI. Combine retrieval-augmented generation with autonomous agents for smarter knowledge access.
Our Solution
https://cdn.sanity.io/images/qdztmwl3/production/19bffad385d6c65220af39e92cc10eb129497ad6-1920x1080.png
auto
Executive Summary
A cloud-native, voice-enabled agentic RAG pipeline engineered to transform static documents into an interactive, context-grounded conversational experience. Built using LlamaParse for document extraction, NVIDIA NIM models for embeddings and LLM inference, Pinecone for vector storage and retrieval, and ElevenLabs for natural speech synthesis, enabling accurate, source-verified answers delivered through both text and high-quality audio.
Challenges
Enterprise-critical information is buried in PDFs, reports, and knowledge bases, making it slow and difficult to access when needed
Lock
Knowledge Locked in Static Documents
Most RAG solutions rely only on text-based Q&A, lacking voice-first or multimodal interfaces that enable natural, intuitive interactions
File
Limited Interaction in Existing RAG Systems
Without strong guardrails and source verification, language models can drift beyond document context and generate unreliable responses.
Check
Risk of Ungrounded or Inaccurate Answers
Solution Overview
We implemented an end-to-end, voice-first RAG application. A FastAPI backend ingests documents (via upload or URL) and transforms them into a conversational question-answering agent. The system ensures every response is strictly grounded in the retrieved document content and delivered in clear, natural speech.
How it Works
7b54316e353c
image
image-fd597a48ad43a8b149de76df4e1df312de1010d2-4366x3457-png
reference
Agentic RAG with voice-based output
339c67d6dd5d
block
bcdae70f546f
span
strong
Ingestion & Parsing:
ce82320be97b
The user uploads a document or URL. LlamaParse extracts high-fidelity text from it.
bullet
normal
69b588d2c4cc
7fe2e5357807
Vectorization & Indexing:
a9a5bbd6a655
The extracted text is chunked and embedded using NVIDIA’s nv-embed-v1 model (via NIMs). These vectors are stored in a Pinecone index for fast similarity search.
59ec270e9549
aaa42276c8ab
Query & Retrieval:
53cef2cc4109
When a question is asked, it is vectorized and sent to Pinecone. The system retrieves the most relevant text chunks from the document as context.
c2182c25edbb
a51158fe2eca
Agentic Answering:
f3ccbea312bb
A specialized agent (powered by NVIDIA’s qwen/qwen3-235b-a22b model) generates an answer using only the retrieved context, avoiding hallucinations.
5090c84d5350
5360ca54f8fb
Voice Synthesis:
032243c3c0e6
The final text answer is sent to ElevenLabs, which generates a polished, human-like audio stream. The user receives both the text answer and the synthesized speech.
https://cdn.sanity.io/images/qdztmwl3/production/5efcfa1be0e12a6b3534f609e6a63c133b94b650-1908x1083.png
User Interface (Web Application Dashboard)
https://cdn.sanity.io/images/qdztmwl3/production/bd5ddc4a5637b86f5024c7681b8cd43091ed5bb7-1908x1147.png
Conversational AI Chat Window
https://cdn.sanity.io/images/qdztmwl3/production/c0b15895f4f3fd23e7cacdd672c09d181b3964d0-1908x1249.png
URL-Based Document Query – Response Preview (Sample 1)
https://cdn.sanity.io/images/qdztmwl3/production/ab71787fc5d2455354901c56704c8b648edb5e23-1908x1249.png
URL-Based Document Query – Response Preview (Sample 2)
Key Benefits
Provides answers in both text and spoken form, improving engagement
Layers
Multi-Modal Interaction
Leverages NVIDIA’s models for embeddings and generation, boosting accuracy and performance
ArrowUp
State-of-the-Art AI
Uses serverless services like Pinecone and NIMs to handle large workloads with low latency
ArrowRight
Scalable & Managed
The RAG pipeline ensures quick responses that are factually grounded in the source documents
Navigation
Fast & Grounded
Integrates ElevenLabs for natural, expressive text-to-speech output
TrendingUp
High-Quality Audio
Exposes a simple REST API for smooth integration with existing applications
Upload
Easy Integration
Key Outcomes with NVIDIA Powered voice based Agentic RAG
Target
Grounded Answers
The agent only uses the retrieved document content to answer, eliminating hallucinations
Tool
Voice-Enabled Output
Users receive high-quality audio responses along with text
Broad Content Support
Handles diverse input formats (complex PDFs and other docs, plus URLs)
Scalable Performance
Built on NVIDIA NIMs and a serverless Pinecone DB to achieve low-latency, enterprise-grade throughput
Technical Foundation
FastAPI (Python) for building high-performance, scalable APIs and orchestration services
Code
Backend
LlamaParse for advanced, accurate extraction of structured content from complex documents
Building
Document Processing
Pinecone as a serverless vector database enabling fast, scalable semantic search and retrieval
Box
Vector Database
NVIDIA NIMs using nv-embed-v1 for embeddings and Qwen/Qwen3-235B-A22B for reasoning and generation
AI Models
Agno framework to manage agentic workflows, tool usage, and controlled reasoning logic
Bot
AI Orchestration
ElevenLabs API for state-of-the-art, natural-sounding text-to-speech output
Unlock
Voice & Speech
Conclusion
This agentic, voice-enabled RAG pipeline demonstrates how enterprise knowledge can evolve from static repositories into intelligent, conversational, and accessible digital assistants. By combining grounded retrieval, agentic reasoning, and natural speech output, the solution elevates enterprise information consumption from searching and reading to asking and listening, enabling faster, smarter, and more intuitive decision-making.
Unlock enterprise knowledge with a voice-enabled, agentic RAG system that delivers grounded answers through text and natural speech, fast, secure, and ready to integrate.
Book a Demo
https://calendly.com/contact-genaiprotos/3xde
NVIDIA Powered voice based Agentic RAG

Executive Summary
A cloud-native, voice-enabled agentic RAG pipeline engineered to transform static documents into an interactive, context-grounded conversational experience. Built using LlamaParse for document extraction, NVIDIA NIM models for embeddings and LLM inference, Pinecone for vector storage and retrieval, and ElevenLabs for natural speech synthesis, enabling accurate, source-verified answers delivered through both text and high-quality audio.
Challenges
Knowledge Locked in Static Documents
Enterprise-critical information is buried in PDFs, reports, and knowledge bases, making it slow and difficult to access when needed
Limited Interaction in Existing RAG Systems
Most RAG solutions rely only on text-based Q&A, lacking voice-first or multimodal interfaces that enable natural, intuitive interactions
Risk of Ungrounded or Inaccurate Answers
Without strong guardrails and source verification, language models can drift beyond document context and generate unreliable responses.
Solution Overview
We implemented an end-to-end, voice-first RAG application. A FastAPI backend ingests documents (via upload or URL) and transforms them into a conversational question-answering agent. The system ensures every response is strictly grounded in the retrieved document content and delivered in clear, natural speech.
How it Works
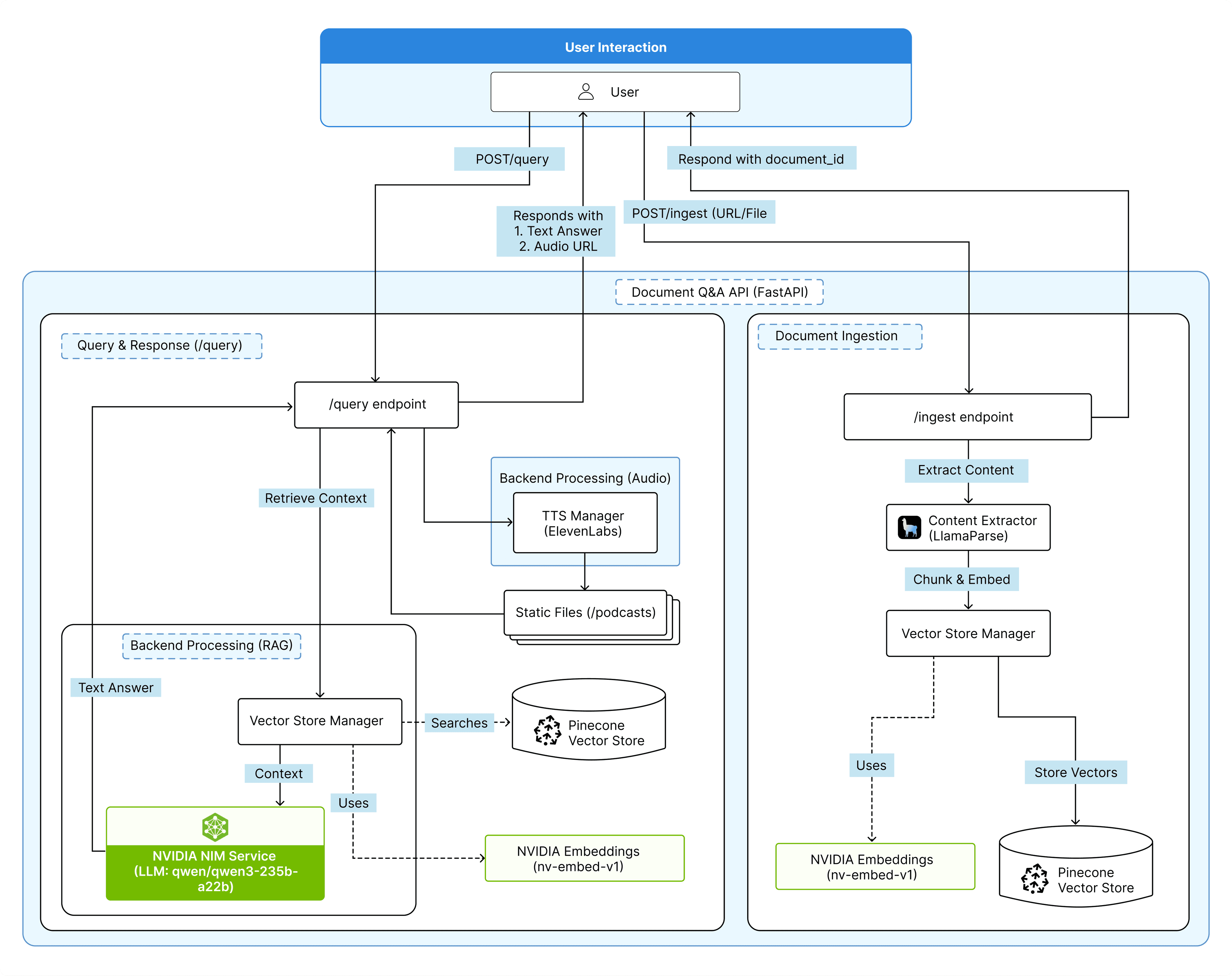
Agentic RAG with voice-based output
- Ingestion & Parsing: The user uploads a document or URL. LlamaParse extracts high-fidelity text from it.
- Vectorization & Indexing: The extracted text is chunked and embedded using NVIDIA’s nv-embed-v1 model (via NIMs). These vectors are stored in a Pinecone index for fast similarity search.
- Query & Retrieval: When a question is asked, it is vectorized and sent to Pinecone. The system retrieves the most relevant text chunks from the document as context.
- Agentic Answering: A specialized agent (powered by NVIDIA’s qwen/qwen3-235b-a22b model) generates an answer using only the retrieved context, avoiding hallucinations.
- Voice Synthesis: The final text answer is sent to ElevenLabs, which generates a polished, human-like audio stream. The user receives both the text answer and the synthesized speech.
User Interface (Web Application Dashboard)
Conversational AI Chat Window
URL-Based Document Query – Response Preview (Sample 1)
URL-Based Document Query – Response Preview (Sample 2)
Key Benefits
Key Outcomes with NVIDIA Powered voice based Agentic RAG
Grounded Answers
The agent only uses the retrieved document content to answer, eliminating hallucinations
Voice-Enabled Output
Users receive high-quality audio responses along with text
Broad Content Support
Handles diverse input formats (complex PDFs and other docs, plus URLs)
Scalable Performance
Built on NVIDIA NIMs and a serverless Pinecone DB to achieve low-latency, enterprise-grade throughput
Technical Foundation
Backend
FastAPI (Python) for building high-performance, scalable APIs and orchestration services
Document Processing
LlamaParse for advanced, accurate extraction of structured content from complex documents
Vector Database
Pinecone as a serverless vector database enabling fast, scalable semantic search and retrieval
AI Models
NVIDIA NIMs using nv-embed-v1 for embeddings and Qwen/Qwen3-235B-A22B for reasoning and generation
AI Orchestration
Agno framework to manage agentic workflows, tool usage, and controlled reasoning logic
Voice & Speech
ElevenLabs API for state-of-the-art, natural-sounding text-to-speech output
Conclusion
This agentic, voice-enabled RAG pipeline demonstrates how enterprise knowledge can evolve from static repositories into intelligent, conversational, and accessible digital assistants. By combining grounded retrieval, agentic reasoning, and natural speech output, the solution elevates enterprise information consumption from searching and reading to asking and listening, enabling faster, smarter, and more intuitive decision-making.
