NVIDIA AI Blog Creator
NVIDIA AI Blog Creator
See how NVIDIA AI and RAG enable reliable, high-throughput content automation.
NVIDIA AI Blog Creator | GenAI Protos
Generate SEO-optimized blog content automatically using NVIDIA AI Blog Creator . Save time and scale content creation with GenAI Protos' AI blog creator solution.
Our Solution
https://cdn.sanity.io/images/qdztmwl3/production/84ea35be8a2da4a9bf15e82de75960b32e27af5c-1920x1080.png
auto
Executive Summary
The NVIDIA AI Blog Creator is a FastAPI-based service designed to automatically generate high-quality technical blogs using a user-provided document and topic. It combines Retrieval-Augmented Generation (RAG) with a multi-agent architecture to outline, research, write, and review blog content in a structured and repeatable manner. By grounding every generated section in ingested source material, the system ensures accuracy, relevance, and scalability for enterprise content workflows.
Challenges
Organizations and content teams must produce more articles, faster, using existing internal documents or research data.
ArrowBigUpDash
High demand for content
Writing quality, detailed content is time-consuming; scaling output usually requires more human writers.
ClipboardPen
Manual Effort
Generated content must stay true to the provided sources, not just general knowledge, to ensure contextually correct information.
FileCheck
Relevance and accuracy
Handling many content-generation requests concurrently without cross-contamination of data is challenging.
Activity
Scalability
Solution Overview
The NVIDIA AI Blog Creator addresses these challenges using a RAG-driven multi-agent system orchestrated through a FastAPI backend. Source documents are ingested, parsed, chunked, embedded, and stored in a vector database. When a blog topic is submitted, specialized AI agents collaborate to generate a structured outline, ask targeted questions, retrieve relevant document context, write content, and perform a final quality review. This approach balances automation with accuracy, ensuring outputs remain aligned with the original source material.
How it Works
e246dc7e5c3c
block
3e84074061f9
span
Document Ingestion: User uploads a source document (PDF, DOCX) via /ingest. The file is parsed to Markdown using LlamaParse, then split into overlapping 512-character chunks (50-char overlap) to fit the embedding model.
bullet
normal
725b8ba36691
9db98de330a1
Embedding & Storage: Each text chunk is converted into a 1024-dimensional vector by NVIDIA’s nv-embed-v1 model and stored in a Pinecone index under a new namespace. The endpoint returns this namespace ID.
50c482ba725f
bc333f0eef2a
Start Generation: User submits the topic and namespace to. A RAG retrieval tool is instantiated, configured to query only that document’s Pinecone namespace.
b5be037959a7
c310cbae515a
Outline Generation: OutlineGeneratorAgent creates a structured blog outline from the topic.
59a41e160d07
bd44c730b920
Question Generation: QuestionGeneratorAgent formulates targeted research questions based on the outline.
7a1e93cd3562
78ae985cf91c
Content Generation: ContentGeneratorAgent iteratively uses the RAG tool to fetch relevant chunks from the ingested document for each question, synthesizing the blog sections.
df6137807680
a7f0b5398273
Critique & Review: CriticAgent reviews the draft for accuracy, clarity, and completeness against the outline and retrieved facts.
0b619858cf03
d89aae05affe
Streaming Output: Progress updates (outline, questions, draft segments) and the final blog post (with the critic’s feedback) are streamed back to the user in real time via FastAPI’s
e13f7490d483
image
AI Blog Creator Architecture Diagram
image-58f9e5fdfd406dc0ffb8ea94a4e1f5cddfd04769-4366x3883-png
reference
https://cdn.sanity.io/images/qdztmwl3/production/1fc13b2a1ed690cfcc768e709968a78352f69b51-1908x1398.png
Upload Document
https://cdn.sanity.io/images/qdztmwl3/production/8d239ba7885412a4e8d510ee0bdaad0e2e4adf68-1908x1494.png
Document Uploaded Successfully
https://cdn.sanity.io/images/qdztmwl3/production/d03d5ba3716f789fcedbfa3180d8bed1450f1519-1908x1494.png
Add the Blog Topic
https://cdn.sanity.io/images/qdztmwl3/production/a4f67912759564af245713209836b1257bf60cbe-1908x1494.png
Writing Blog Content
https://cdn.sanity.io/images/qdztmwl3/production/41c6895e6f4f162f15c38aed3a4988c96f214008-1027x648.png
Generated Blog
Key Benefits
Automates blog creation without increasing headcount.
FastForward
Faster Content Delivery
RAG ensures every generated section is backed by source documents.
FileOutput
Reliable and Grounded Output
API-first design supports parallel content generation at scale.
Scalable Architecture
Namespace-level separation prevents cross-document leakage.
Table
Data Privacy and Isolation
Modular agents and tooling allow easy customization or expansion.
Puzzle
Extensible Design
Built on NVIDIA models and modern AI infrastructure components.
Cpu
Production-Grade AI Stack
Key Outcomes with NVIDIA AI Blog Creator
Target
Automated Content Production
Substantially reduces manual effort and accelerates the end-to-end blog writing process through AI-driven automation.
Contextual Accuracy
Retrieval-Augmented Generation (RAG) ensures that every generated article is grounded in the uploaded source document, keeping facts aligned and reliable.
The API-driven, multi-agent architecture supports high-throughput, concurrent content generation without compromising data integrity.
Modular & Extensible Architecture
Built using FastAPI and agent frameworks such as Agno and LangChain, enabling easy customization, extension, and integration with existing enterprise tools.
Each document ingestion is assigned a unique Pinecone namespace, ensuring strict data isolation and preventing cross-document data leakage.
High-Performance AI
Leverages NVIDIA’s nv-embed-v1 for embeddings and qwen3-coder-480B for reasoning, delivering fast, enterprise-grade AI performance.
Technical Foundation
FastAPI (asynchronous REST APIs) StreamingResponse for real-time progress updates
Server
Backend & API
Agno (agent definition, orchestration, and execution) Multi-agent workflow (Outline, Question, Content, Critic)
Workflow
AI Agent Framework
LlamaParse for document parsing RecursiveCharacterTextSplitter Chunk size: 512 characters Overlap: 50 characters
FileText
Document Processing
Pinecone (serverless vector database) Namespace-based data isolation per document ingestion
Radar
Retrieval & Vector Storage
NVIDIA Embeddings (nvidia/nv-embed-v1) 1024-dimension vector representation
ChartScatter
Embeddings
NVIDIA NIM Model: qwen/qwen3-coder-480b-a35b-instruct
Bot
Large Language Model
Retrieval-Augmented Generation (RAG) Dynamic retrieval tools scoped per namespace
GitBranch
AI Pattern
Conclusion
The NVIDIA AI Blog Creator demonstrates how multi-agent systems combined with RAG can move AI content generation from experimental to production-ready. Instead of relying on a single large model to “write everything,” the system breaks the task into logical steps planning, questioning, writing, and reviewing each handled by a specialized agent. This mirrors real editorial workflows while preserving automation, accuracy, and scalability. For organizations managing large volumes of technical content derived from internal documents, this approach provides a clear blueprint: isolate data, ground generation in retrieval, and orchestrate intelligence through agents. The result is not just faster blog creation, but a more reliable and controllable AI content pipeline.
Move AI Content Creation from Experiment to Production
This architecture shows how RAG and multi-agent systems can be applied to build accurate, scalable AI content workflows grounded in enterprise data. GenAI Protos works on designing and deploying such production-ready GenAI systems with a strong focus on engineering, data reliability, and scalability.
Book a Demo
https://calendly.com/contact-genaiprotos/3xde
NVIDIA AI Blog Creator

Executive Summary
The NVIDIA AI Blog Creator is a FastAPI-based service designed to automatically generate high-quality technical blogs using a user-provided document and topic. It combines Retrieval-Augmented Generation (RAG) with a multi-agent architecture to outline, research, write, and review blog content in a structured and repeatable manner. By grounding every generated section in ingested source material, the system ensures accuracy, relevance, and scalability for enterprise content workflows.
Challenges
High demand for content
Organizations and content teams must produce more articles, faster, using existing internal documents or research data.
Manual Effort
Writing quality, detailed content is time-consuming; scaling output usually requires more human writers.
Relevance and accuracy
Generated content must stay true to the provided sources, not just general knowledge, to ensure contextually correct information.
Scalability
Handling many content-generation requests concurrently without cross-contamination of data is challenging.
Solution Overview
The NVIDIA AI Blog Creator addresses these challenges using a RAG-driven multi-agent system orchestrated through a FastAPI backend. Source documents are ingested, parsed, chunked, embedded, and stored in a vector database. When a blog topic is submitted, specialized AI agents collaborate to generate a structured outline, ask targeted questions, retrieve relevant document context, write content, and perform a final quality review. This approach balances automation with accuracy, ensuring outputs remain aligned with the original source material.
How it Works
- Document Ingestion: User uploads a source document (PDF, DOCX) via /ingest. The file is parsed to Markdown using LlamaParse, then split into overlapping 512-character chunks (50-char overlap) to fit the embedding model.
- Embedding & Storage: Each text chunk is converted into a 1024-dimensional vector by NVIDIA’s nv-embed-v1 model and stored in a Pinecone index under a new namespace. The endpoint returns this namespace ID.
- Start Generation: User submits the topic and namespace to. A RAG retrieval tool is instantiated, configured to query only that document’s Pinecone namespace.
- Outline Generation: OutlineGeneratorAgent creates a structured blog outline from the topic.
- Question Generation: QuestionGeneratorAgent formulates targeted research questions based on the outline.
- Content Generation: ContentGeneratorAgent iteratively uses the RAG tool to fetch relevant chunks from the ingested document for each question, synthesizing the blog sections.
- Critique & Review: CriticAgent reviews the draft for accuracy, clarity, and completeness against the outline and retrieved facts.
- Streaming Output: Progress updates (outline, questions, draft segments) and the final blog post (with the critic’s feedback) are streamed back to the user in real time via FastAPI’s
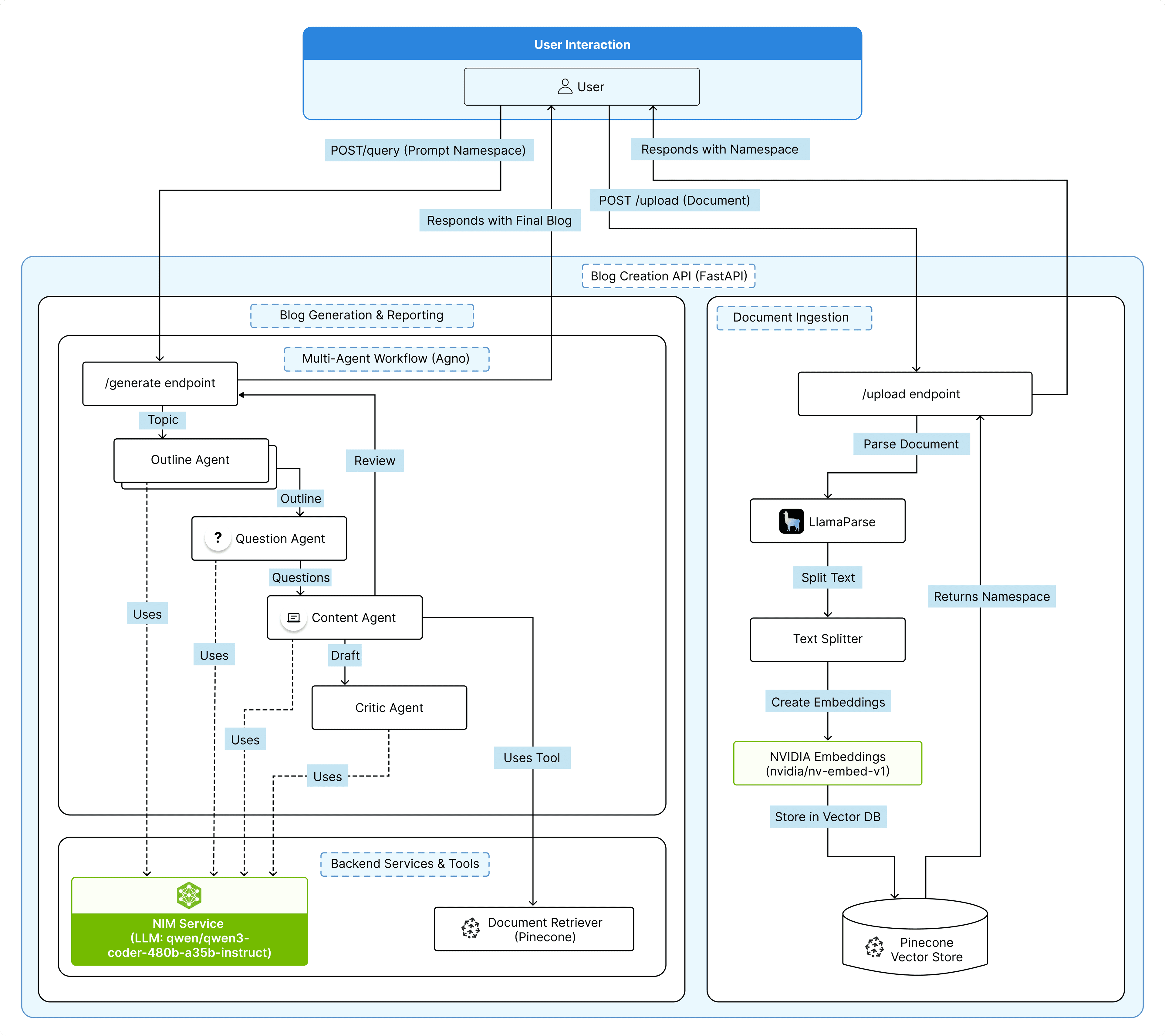
AI Blog Creator Architecture Diagram
Upload Document
Document Uploaded Successfully
Add the Blog Topic
Writing Blog Content
Generated Blog
Key Benefits
Key Outcomes with NVIDIA AI Blog Creator
Automated Content Production
Substantially reduces manual effort and accelerates the end-to-end blog writing process through AI-driven automation.
Contextual Accuracy
Retrieval-Augmented Generation (RAG) ensures that every generated article is grounded in the uploaded source document, keeping facts aligned and reliable.
Scalability
The API-driven, multi-agent architecture supports high-throughput, concurrent content generation without compromising data integrity.
Modular & Extensible Architecture
Built using FastAPI and agent frameworks such as Agno and LangChain, enabling easy customization, extension, and integration with existing enterprise tools.
Data Privacy and Isolation
Each document ingestion is assigned a unique Pinecone namespace, ensuring strict data isolation and preventing cross-document data leakage.
High-Performance AI
Leverages NVIDIA’s nv-embed-v1 for embeddings and qwen3-coder-480B for reasoning, delivering fast, enterprise-grade AI performance.
Technical Foundation
Backend & API
FastAPI (asynchronous REST APIs) StreamingResponse for real-time progress updates
AI Agent Framework
Agno (agent definition, orchestration, and execution) Multi-agent workflow (Outline, Question, Content, Critic)
Document Processing
LlamaParse for document parsing RecursiveCharacterTextSplitter Chunk size: 512 characters Overlap: 50 characters
Retrieval & Vector Storage
Pinecone (serverless vector database) Namespace-based data isolation per document ingestion
Embeddings
NVIDIA Embeddings (nvidia/nv-embed-v1) 1024-dimension vector representation
Large Language Model
NVIDIA NIM Model: qwen/qwen3-coder-480b-a35b-instruct
AI Pattern
Retrieval-Augmented Generation (RAG) Dynamic retrieval tools scoped per namespace
Conclusion
The NVIDIA AI Blog Creator demonstrates how multi-agent systems combined with RAG can move AI content generation from experimental to production-ready. Instead of relying on a single large model to “write everything,” the system breaks the task into logical steps planning, questioning, writing, and reviewing each handled by a specialized agent. This mirrors real editorial workflows while preserving automation, accuracy, and scalability. For organizations managing large volumes of technical content derived from internal documents, this approach provides a clear blueprint: isolate data, ground generation in retrieval, and orchestrate intelligence through agents. The result is not just faster blog creation, but a more reliable and controllable AI content pipeline.
