Introduction
The first AI prototype often starts with a hosted API. That is practical. It is fast, accessible, and low-ops. The problem appears later when Security, Legal, Compliance, or a customer asks where the data goes, who can access it, how logs are handled, and what happens when the provider changes the model.
At that point, deployment is no longer a technical preference. It becomes an architecture decision that controls what the business can safely ship.
For regulated or sensitive use cases, the model deployment path should be decided before the build. Waiting until after the first working feature creates expensive rework.
GenAI Protos’ Private AI expertise is the most relevant internal link for readers considering private, on-prem, or sovereign AI deployment.
Business impact: Deployment mistakes become expensive because they are discovered after product, security, and legal expectations are already set. Choosing the model infrastructure early protects budget, timeline, and compliance posture by preventing a successful prototype from becoming an architecture rewrite.
The Three Deployment Models
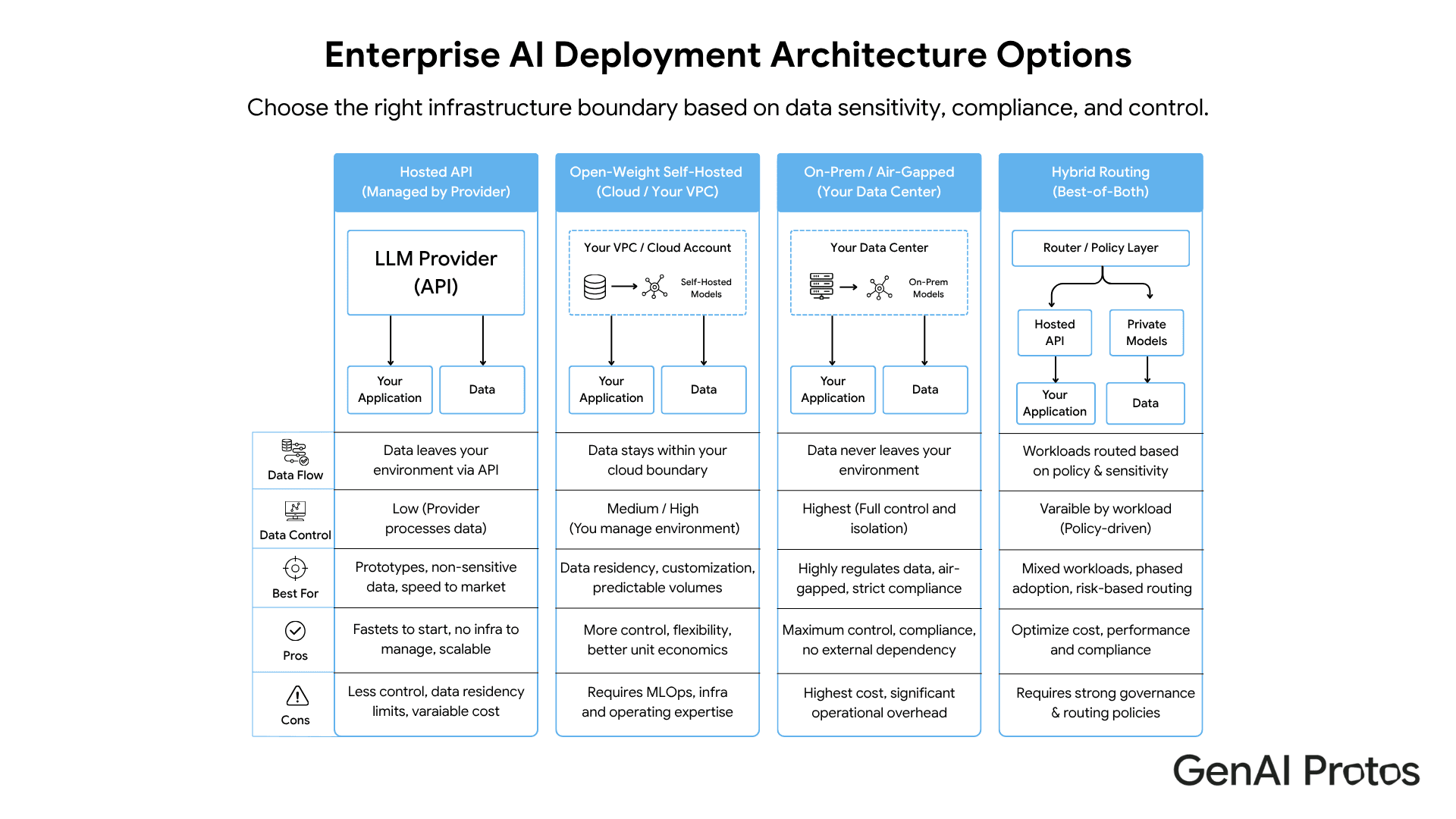
1. Hosted API
The model runs on a third-party provider’s infrastructure. Your application sends a request and receives a response.
Best for:
prototypes
non-sensitive data
low to medium volume
fast experimentation
teams without ML infrastructure
Watchouts:
data leaves your environment
limited model control
provider-side changes
contractual and logging questions
cost growth at scale
2. Open-weight self-hosted
The model weights run on infrastructure you control, often in your cloud account or private environment.
Best for:
sensitive enterprise workloads
stronger data residency
customization
high-volume inference
teams with platform or MLOps capability
Watchouts:
GPU and infrastructure operations
model serving complexity
monitoring and patching
scaling and incident response
ongoing model management
3. On-premise or air-gapped
The model, compute, and data stay inside your physical or isolated network boundary.
Best for:
highly sensitive data
strict residency or isolation
defense, healthcare, critical infrastructure, or restricted environments
workloads where no external inference path is acceptable
Watchouts:
highest cost
slowest setup
hardware procurement
specialist operations
model update complexity
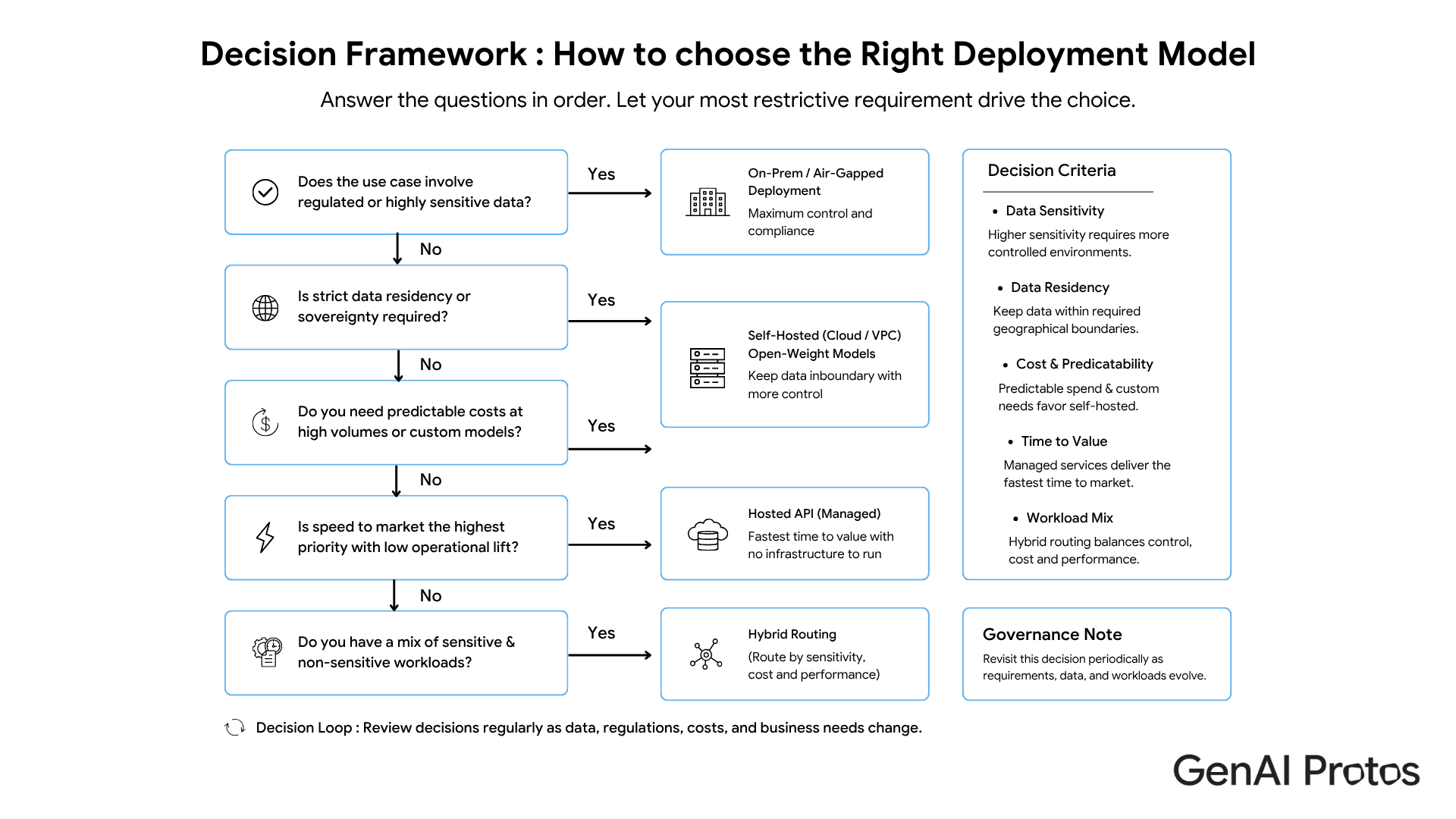
Six Criteria That Drive the Decision
Use these criteria before selecting infrastructure.
1. Data sensitivity
If the workload includes personal, patient, financial, legal, or proprietary data, deployment control matters immediately.
2. Regulatory obligation
GDPR, HIPAA, EU AI Act, sector rules, and customer contracts may affect where data can be processed and what evidence you must produce.
3. Latency and availability
Hosted APIs depend on external networks and provider limits. Self-hosted and on-prem models give more control over latency and availability engineering.
4. Production-scale cost
Hosted APIs are often cheaper to start. Self-hosting can become attractive when usage is sustained and high, but only if operational costs are included.
5. Customization
If your model needs domain adaptation, private fine-tuning, or behavior control using sensitive data, self-hosted or on-prem options may be safer.
6. Team capability
Self-hosting is not “free control.” It requires model serving, security, monitoring, scaling, patching, and incident response.
The practical question: Which deployment model gives enough control for the use case without creating operational burden the team cannot sustain?
Hosted vs Self-Hosted vs On-Prem
| Dimension | Hosted API | Open-weight self-hosted | On-prem / air-gapped |
|---|---|---|---|
| Speed to start | Fastest | Moderate | Slowest |
| Data control | Lowest | High | Highest |
| Operational burden | Lowest | High | Highest |
| Customization | Limited to provider options | Strong | Strongest |
| Compliance evidence | Depends on provider | Controlled by your team | Fully controlled |
| Latency control | Limited | Strong | Strong |
| Cost at low volume | Usually favorable | Usually higher | Highest |
| Cost at high volume | Can rise quickly | Potentially favorable | Justified only for strict control |
| Best fit | Non-sensitive and early-stage use cases | Sensitive cloud workloads | Maximum-control environments |
For readers comparing private and public model choices, GenAI Protos’ post on
private LLMs vs public LLMs is a natural supporting link.
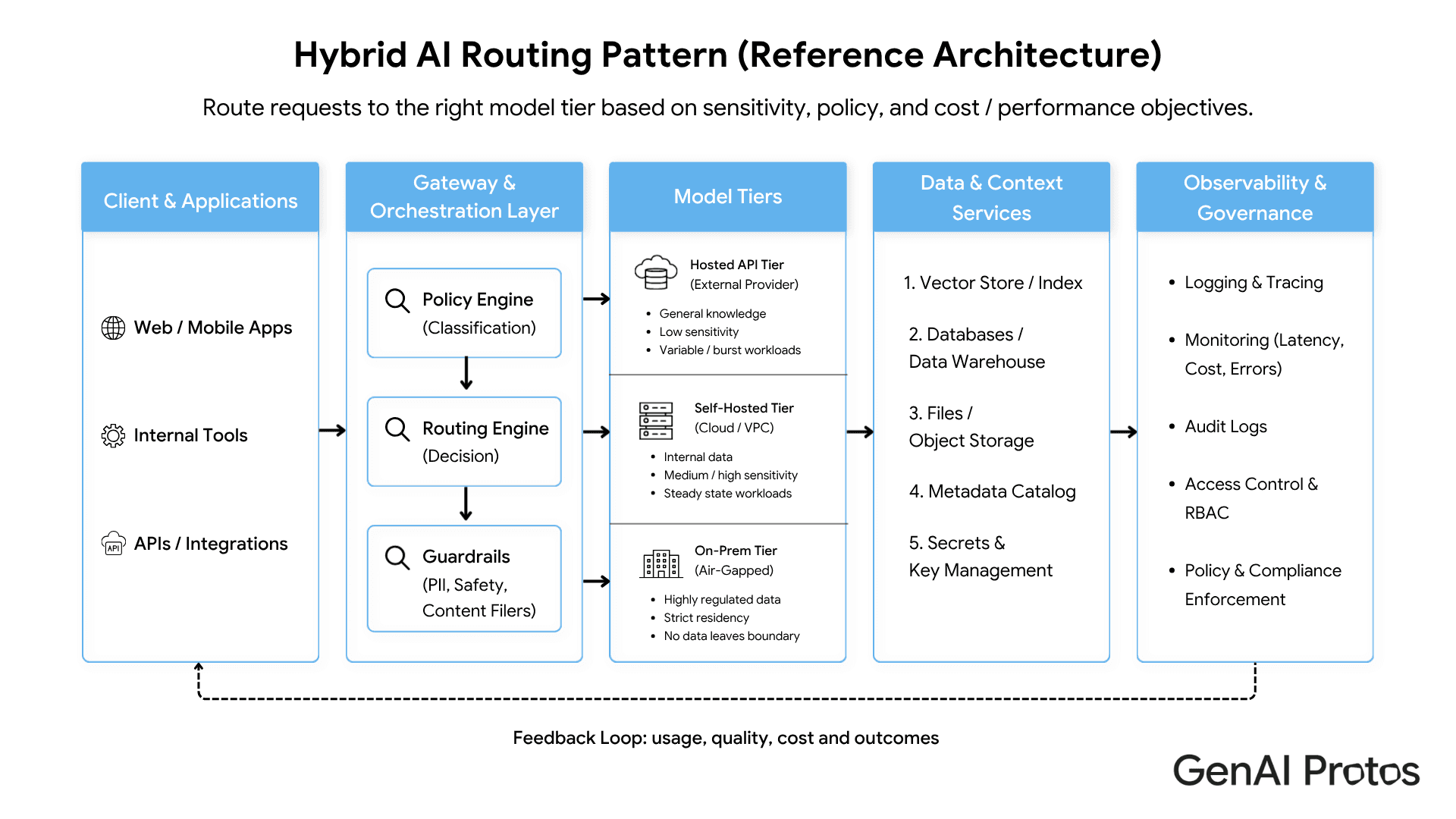
When Hybrid Deployment Is Right
Many enterprises should not choose only one model tier. A hybrid approach can be better.
A practical pattern:
hosted API for public or non-sensitive tasks
self-hosted model for personal, regulated, or proprietary data
on-prem model for highest-sensitivity workflows
routing policy that decides which tier receives each request
The governance boundary is the critical design element. Sensitive data can leak into a hosted tier through prompts, retrieved context, logs, analytics events, or support traces. The boundary must be enforced in code, not only described in a policy document.
GenAI Protos’ De-Risk Your AI Investment is a relevant link for teams evaluating architecture risk before committing to deployment. For teams looking at production AI patterns more broadly, the Enterprise Search and Knowledge Discovery page also reflects how retrieval, governance, and deployment choices connect in real systems.
Mistakes That Make Deployment Expensive
Choosing hosted first and reviewing data flows later
This can force re-architecture after the prototype succeeds.
Underestimating self-hosting operations
Model weights do not include autoscaling, monitoring, patching, or incident response.
Conflating residency with security
Processing data in the right region does not automatically mean the system is secure.
No cost model at production volume
Token, GPU, engineering, and support costs must be compared before scale.
Weak hybrid routing boundaries
Hybrid deployment works only when sensitive data cannot cross into the wrong tier.
Key Takeaways
Deployment is a data control decision first.
Hosted APIs are fastest, but not always suitable for sensitive workloads.
Self-hosted models provide control but require serious operations.
On-prem deployment is justified for maximum-sensitivity environments.
Hybrid deployment is often the best enterprise pattern when governance boundaries are clear.
Conclusion
The right enterprise AI model deployment choice is not about chasing the newest model. It is about matching the deployment architecture to the data, risk, performance, and operational reality of the use case.
Hosted APIs are excellent for speed. Self-hosted open-weight models are strong when control matters. On-premise and air-gapped deployments are the right answer when data sensitivity leaves no room for external inference. Hybrid models often provide the most practical path across mixed workloads.
Decide this before the build. The earlier the deployment model is clear, the less expensive the AI system becomes.
Choose the Right AI Infrastructure Before You Build
GenAI Protos helps enterprise teams evaluate, architect, and deploy AI on infrastructure that fits their data, compliance, and operating model.
Start the conversation



