Introduction
Vector search made enterprise RAG easier to start. It also created a false sense of coverage. A vector retriever can find conceptually similar content, but it can under-rank the exact document a user needs when the query contains a regulation number, SKU, clause ID, drug code, ticket ID, or internal project name.
Keyword search has the opposite problem. It is strong on exact terms but weak on natural-language intent.
Hybrid retrieval exists because enterprise knowledge is messy. Users search with concepts, abbreviations, codes, relationship questions, and incomplete language. One retrieval method cannot serve that full distribution reliably.
GenAI Protos positions this type of work under Enterprise Search and Knowledge Discovery, where search quality depends on both semantic understanding and precise enterprise context.
Business impact: Weak retrieval creates hidden productivity loss. Teams spend time re-searching documents, verifying answers manually, missing exact clauses or identifiers, and losing trust in the knowledge system. A retrieval layer should be judged by whether it reduces search friction for high-value workflows, not just whether it returns semantically similar text.
Why Single-Method Retrieval Breaks
The “keyword vs vector” debate is the wrong debate. The real issue is query diversity.
| Retrieval method | Strength | Failure mode |
|---|---|---|
| Keyword search | Exact terms, identifiers, codes, citations | Misses paraphrases and intent |
| Vector search | Concepts, natural language, semantic similarity | Underweights rare exact terms |
| Graph retrieval | Relationships, multi-hop questions, entity paths | Requires maintained entity data |
In a legal knowledge base, a user may search for “termination language similar to this clause.” That is semantic. Another user may search for “Section 4.2(b).” That is exact. A third may ask, “Which contracts with this supplier include a change-of-control obligation?” That is relational.
A pure vector architecture is likely to perform well for the first query, inconsistently for the second, and poorly for the third unless the relationship is directly stated in a retrieved chunk.
Hybrid retrieval fixes this by allowing the system to treat query types differently without forcing users to choose a search mode.
How Hybrid Retrieval Works
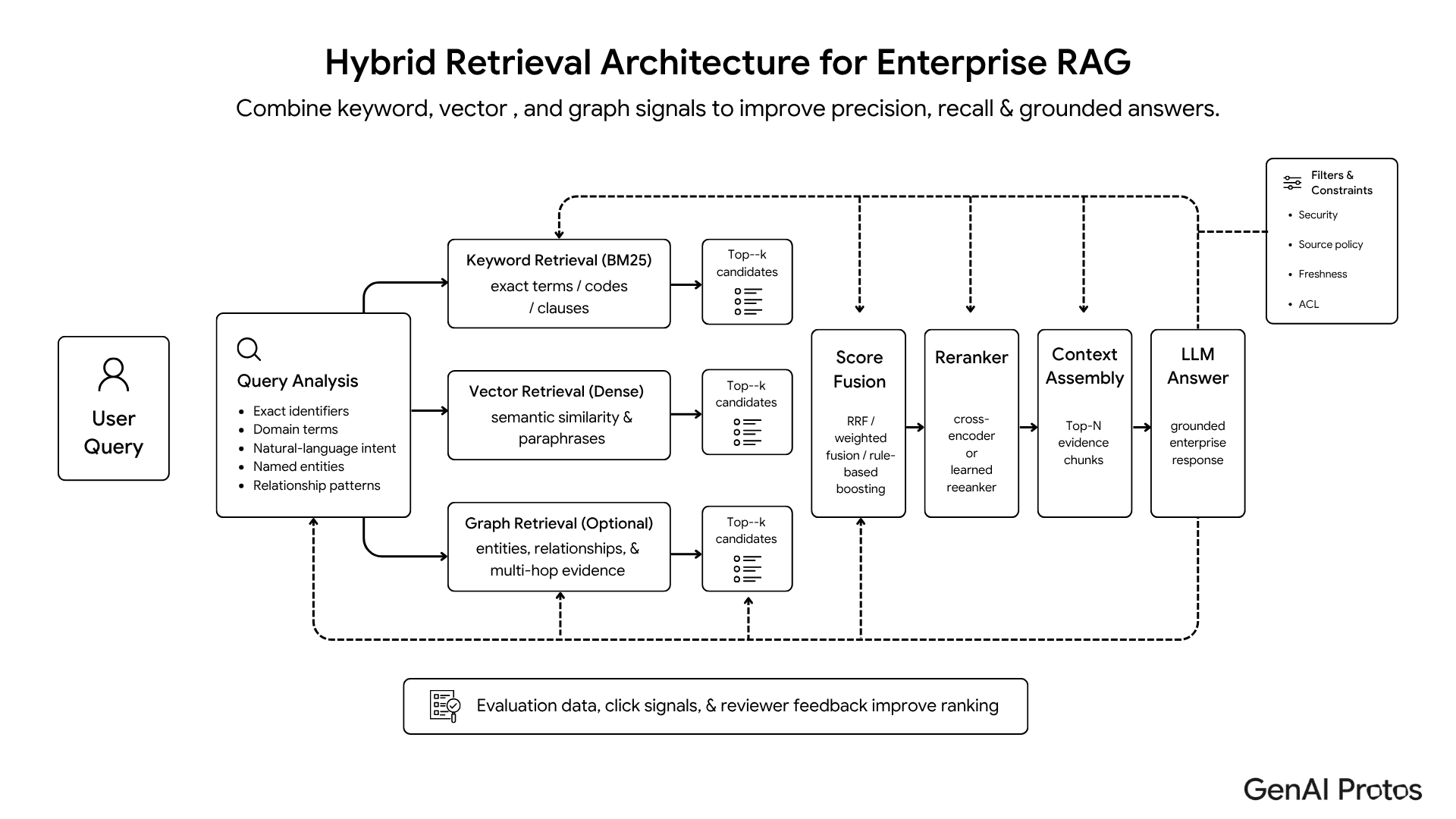
A practical hybrid retrieval pipeline has four steps.
1. Query Analysis
The system inspects the query for intent signals:
exact identifiers
domain terminology
natural-language concepts
named entities
relationship patterns
compliance or policy language
This does not need to be overly complex. Even basic query classification helps decide which retrieval signals should carry more weight.
2. Parallel Retrieval
The system runs keyword and vector retrieval in parallel. If graph retrieval is included, entity extraction triggers graph traversal at the same time.
Parallel execution matters because sequential calls add avoidable latency.
3. Score Fusion
Each retrieval method returns candidates with different scoring behavior. Fusion combines them into one candidate list.
Common approaches include:
weighted score fusion
reciprocal rank fusion
learned reranking
rule-based boosting for identifiers and regulated terms
The important point is that fusion should not simply average scores. It should preserve the signal that matters for the query.
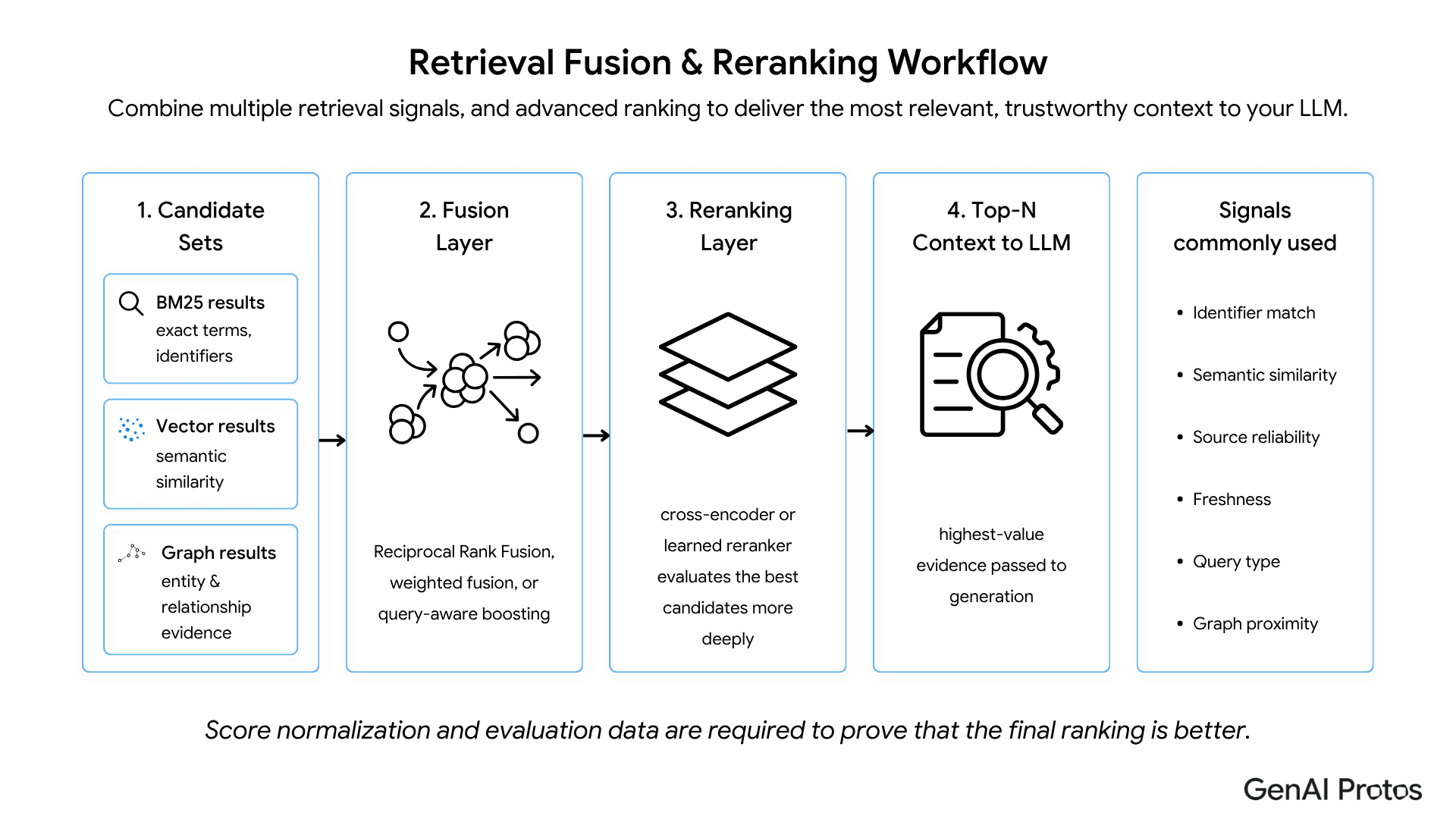
4. Reranking and Context Assembly
A reranker evaluates the top candidates more deeply and selects the context that will be passed to the LLM. This is where hybrid retrieval becomes useful for RAG: better context leads to more grounded answers.
For broader RAG system design, GenAI Protos’ post on 8 RAG architecture patterns is a natural supporting link.
Choosing the Right Architecture Depth
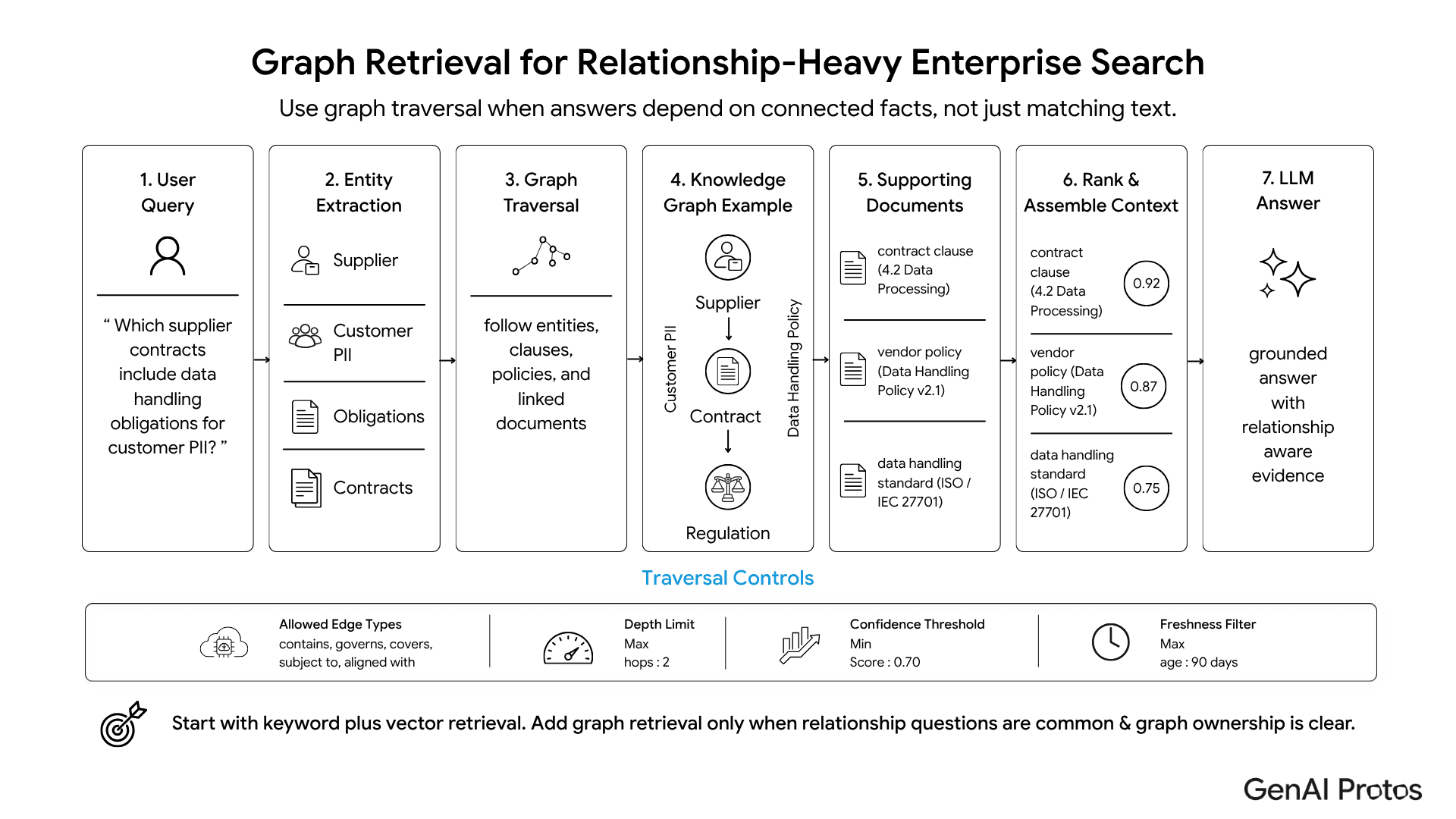
Not every team needs graph retrieval on day one. Use architecture depth based on query distribution.
| Architecture | Best for | Risk |
|---|---|---|
| Pure keyword | Known-term search and structured records | Poor semantic recall |
| Pure vector | General Q&A over clean documents | Weak exact-match behavior |
| Keyword + vector hybrid | Most enterprise RAG systems | Needs score normalization |
| Graph-augmented hybrid | Relationship-heavy domains | Needs graph ownership and maintenance |
Use this decision checklist:
Do users search by exact identifiers? Add keyword.
Do users ask natural-language questions? Add vector.
Do users ask relationship questions? Consider graph.
Is the corpus high-risk or compliance-heavy? Add stronger evaluation.
Is latency strict? Run signals in parallel and cap graph timeout.
A good default for most enterprises is keyword + vector with reranking. Add graph when relationship queries become common and entity ownership is clear.
Operating benchmark: Before tuning fusion weights, build a small labeled retrieval set with 200 to 300 query-result examples across exact-term, semantic, and relationship-heavy queries. This gives teams a measurable way to compare pure vector, keyword + vector, and graph-augmented retrieval before choosing architecture depth.
Where Hybrid Retrieval Delivers Value
Legal and contract search
Contracts contain clause numbers, party names, jurisdictions, obligations, and exceptions. Hybrid retrieval helps match exact clause language while still supporting natural-language questions.
GenAI Protos’ Chat with Google Drive for legal services is a relevant internal link because it shows document search across legal-style collections where exact language and broad discovery both matter.
Enterprise SQL and structured data discovery
Hybrid retrieval is useful when structured and unstructured sources meet. A user may ask a business question that needs both schema awareness and natural-language interpretation. GenAI Protos’ Chat with SQL solution demonstrates the adjacent pattern of grounding natural-language questions in actual database structure.
Document extraction and knowledge indexing
Retrieval quality depends on extraction quality. If a document parser loses headings, tables, metadata, or section boundaries, hybrid retrieval cannot recover the missing structure. GenAI Protos’ ParseAI document content extraction solution is relevant because clean extraction creates better retrieval candidates.
Implementation Risks
Implementation Risks
Poor score normalization
Keyword and vector scores are not naturally comparable. Normalize before fusion.
Graph maintenance without ownership
A stale graph can be worse than no graph. Define ownership before adding it.
Sequential retrieval calls
Run retrieval signals in parallel to protect latency.
No evaluation dataset
Without labeled query-result examples, fusion tuning becomes guesswork.
Overbuilding before query analysis
Do not build graph retrieval because it looks advanced. Build it because the queries demand it.
Key Takeaways
Hybrid retrieval is the enterprise default when exact terms and semantic intent both matter.
Keyword search protects identifiers, codes, and regulated terminology.
Vector search protects natural-language recall.
Graph retrieval is valuable when questions depend on relationships.
Evaluation data is required to prove the fusion strategy is actually improving results.
Conclusion
Hybrid retrieval is not about adding complexity for its own sake. It is about matching the retrieval architecture to how enterprise users actually search.
The strongest design starts with query analysis, adds keyword and vector retrieval as the baseline, uses reranking to improve context quality, and adds graph retrieval only when relationship-heavy questions justify the maintenance cost.
For decision-makers, the key takeaway is clear: better retrieval creates better RAG. The model can only answer from the context it receives. If retrieval fails, generation starts from a weak foundation.
Build a Retrieval Layer That Actually Works at Scale
GenAI Protos designs hybrid retrieval systems for enterprise knowledge environments where precision and recall both matter.
Start the conversation



