Introduction
A RAG system can be fast, stable, and wrong at the same time. That is the core production risk. Latency dashboards show whether the service responds. They do not show whether the answer is grounded, whether the right documents were retrieved, or whether a recent change quietly weakened quality for a specific query type.
A RAG evaluation harness solves that problem by making quality visible. It gives engineering and platform leaders a repeatable way to test the pipeline before deployment and monitor it after release. For teams building enterprise RAG applications, this is not a nice-to-have layer. It is the difference between a system that can improve safely and a system nobody wants to touch after launch.
For teams building RAG on enterprise documents, GenAI Protos aligns this pattern with its RAG Applications expertise, where grounded answers, secure company context, and reduced hallucination risk are core delivery goals.
Business impact: Poor RAG evaluation turns every prompt, chunking, index, or model change into an unmanaged risk decision. The cost shows up as support escalations, rework, lower user trust, and slower release cycles because teams cannot prove whether quality improved or declined. A practical production baseline is 100 to 300 representative question-answer-context examples, with regression gates on every retrieval, prompt, and model change.
Why RAG Evaluation Needs Its Own Harness
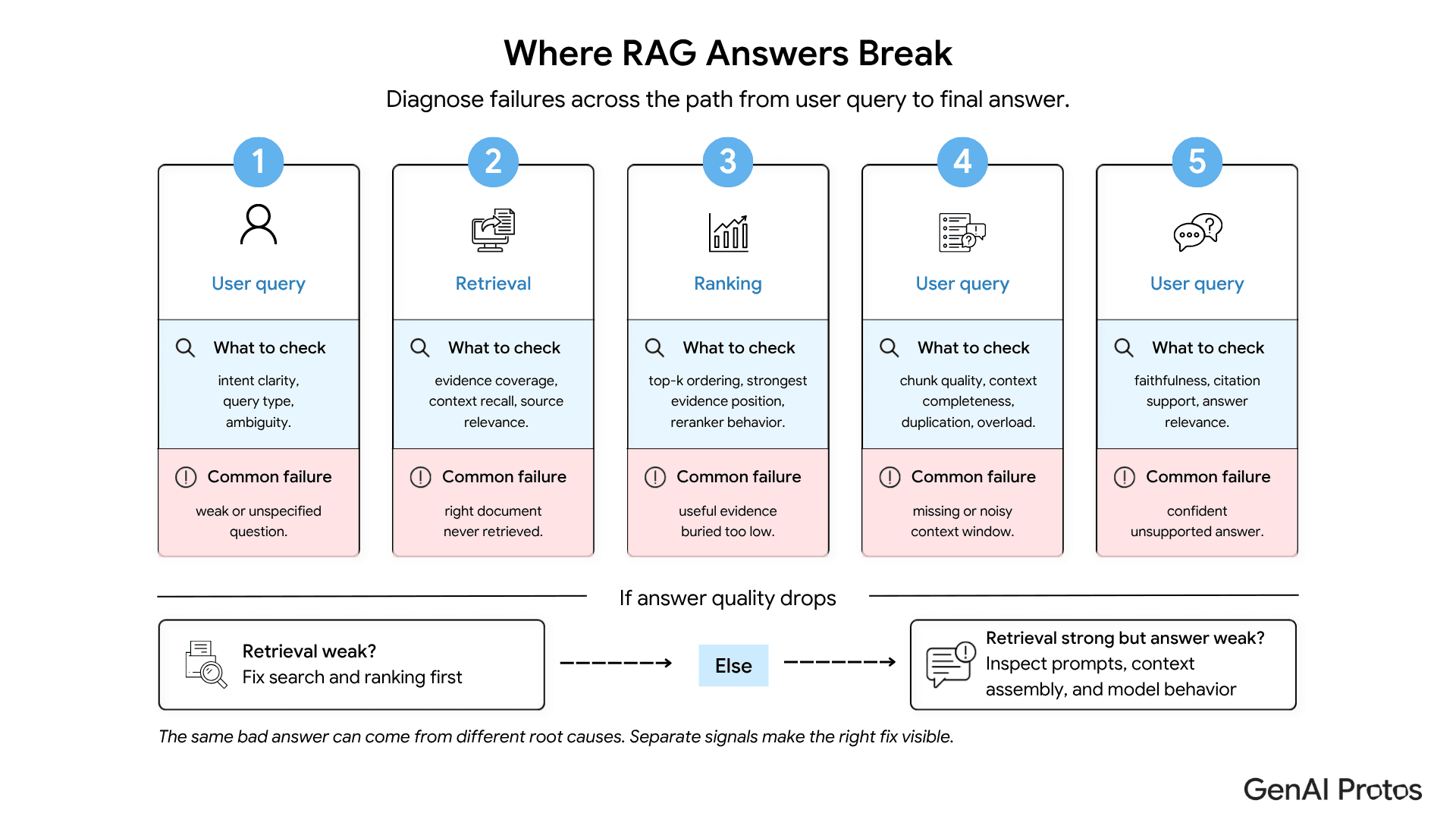
RAG quality is not one score. It is a chain of decisions. The system must understand the query, retrieve relevant content, rank it correctly, assemble a usable context window, and generate an answer that does not invent unsupported claims.
A proper harness checks each layer separately:
Retrieval quality: Did the system fetch the right evidence?
Ranking quality: Did the most useful evidence appear early enough to be used?
Context quality: Was the context complete, clean, and not overloaded?
Generation quality: Did the answer stay faithful to the retrieved material?
Regression risk: Did a change improve one area while damaging another?
This matters because the same bad answer can have different root causes. A vague response may come from weak retrieval. A confident wrong response may come from hallucination. A partially correct response may come from missing context. Without separate signals, teams fix the wrong layer.
The best framing is simple: RAG evaluation is not a report card. It is a diagnostic system.
The Metrics That Matter
A high-value RAG evaluation dashboard should be small enough to act on and deep enough to diagnose failure. The goal is not to track every metric. The goal is to track the metrics that map directly to engineering decisions.
| Metric | What it answers | Why it matters |
|---|---|---|
| Context precision | Are the retrieved chunks relevant? | Prevents noisy context from weakening the answer |
| Context recall | Did we retrieve enough evidence? | Catches missing documents and incomplete answers |
| Mean reciprocal rank | Did the first useful result appear near the top? | Protects systems where top-ranked context dominates generation |
| Faithfulness | Is the answer supported by the retrieved context? | Detects hallucinated or unsupported claims |
| Answer relevance | Did the answer address the user’s question? | Catches correct-but-unhelpful responses |
| Groundedness | Can claims be traced back to source passages? | Supports auditability in regulated workflows |
| Regression pass rate | Did the latest change preserve quality? | Blocks risky releases before they reach users |
The most important principle: measure retrieval and generation separately before looking at end-to-end quality. If final answer quality drops and retrieval quality also dropped, start with retrieval. If retrieval stayed strong but faithfulness dropped, inspect prompts, context assembly, and model behavior.
A RAG evaluation harness should also support quality tiers. A support assistant, compliance assistant, and executive knowledge agent do not need the same thresholds. Risk determines tolerance. A system answering public FAQs can tolerate a different failure profile than a system summarizing policy, contract, medical, or financial content.
The Evaluation Architecture
A practical RAG evaluation harness has five components.
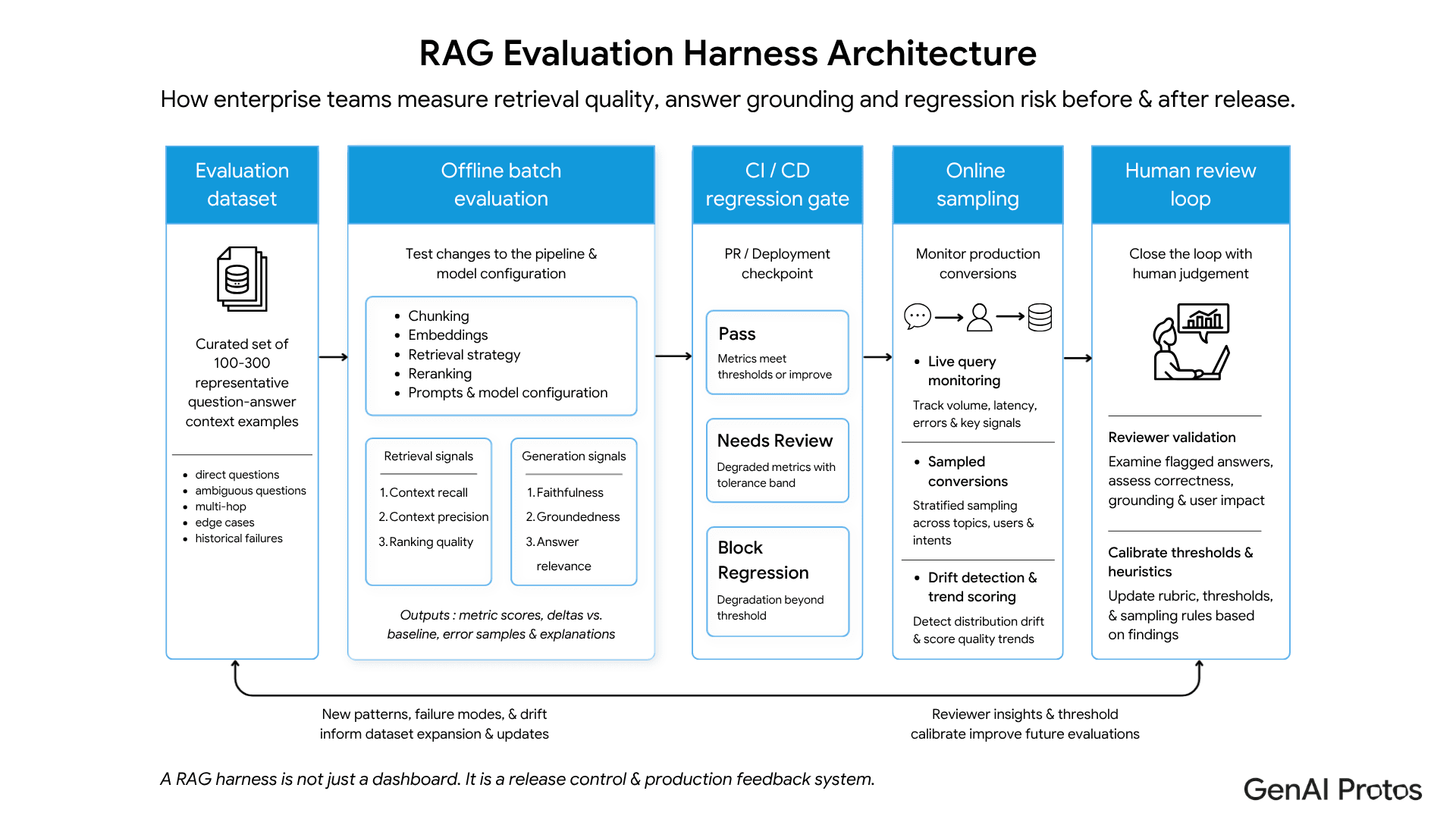
1. Evaluation Dataset
Start with real or realistic user questions. Include direct questions, ambiguous questions, multi-hop questions, edge cases, stale-document cases, and known historical failures. Each item should include the expected answer, the source context, and the reason the question matters.
The dataset is not static. Every production failure should become a future test case.
Operating benchmark: Start with the highest-risk 100 to 300 questions, then expand the set monthly from real failures, edge cases, and new document categories. This keeps the harness aligned to how users actually ask questions, not just how the team expects them to ask.
2. Offline Batch Evaluation
Run this before release. It should test any change to chunking, embedding models, retrieval strategy, prompt templates, reranking logic, or model configuration.
The output should be clear:
improved
unchanged
regressed
needs human review
3. CI/CD Regression Gate
The evaluation result should affect deployment. If a pull request weakens quality on high-risk queries, the pipeline should stop. This turns evaluation from an analyst exercise into an engineering control.
For a deeper view of production RAG architecture patterns, read GenAI Protos’ guide to 8 RAG architecture types.
4. Online Sampling
Offline tests catch known problems. Online monitoring catches production drift. Sample live queries, score retrieval and generation quality, and feed weak examples back into the evaluation dataset.
5. Human Review Loop
Automated scoring is useful, but not enough for nuanced domains. Human reviewers should inspect flagged answers, borderline scores, and high-impact workflows. Their review should improve the test set and recalibrate automated thresholds.
Where the Harness Pays Off
A RAG evaluation harness has the most value when teams need to keep improving the system after launch.
Enterprise Knowledge Assistants
The harness helps teams detect when new documents, rewritten policies, or updated metadata change retrieval behavior. Without it, users discover problems manually.
Compliance and Policy Q&A
The harness supports grounded answers, source traceability, and review trails. This aligns well with systems like the GenAI Protos FactPulse fact-checking solution, where claim verification and evidence tracking are central to trustworthy output.
Developer and Data Knowledge Search
The harness catches coverage gaps when technical documentation, schemas, or internal repositories change. It helps teams see whether the system still answers from the right source.
For broader RAG fundamentals, readers can also review how retrieval-augmented generation systems work.
Common Mistakes to Avoid
Testing only easy queries
This creates false confidence. Include the questions that users actually struggle with.
Measuring generation without retrieval
Most RAG failures start before the model writes the answer. Retrieval metrics must be first-class.
Using one quality threshold for every workflow
Risk levels differ. A compliance assistant needs stricter gates than an internal FAQ assistant.
Treating human feedback as evaluation
User feedback is useful, but late. The harness should catch issues before users report them.
Never refreshing the test set
Your corpus changes. Your users change. Your evaluation dataset must change too.
These risks connect directly to broader AI delivery patterns discussed in GenAI Protos’ post on common AI project delivery mistakes.
Key Takeaways
A RAG evaluation harness measures answer quality, not just uptime.
Retrieval and generation must be evaluated separately.
CI/CD regression gates turn quality into a release control.
Online sampling catches drift that offline tests miss.
Human review improves evaluation quality in high-stakes domains.
Conclusion
RAG systems do not fail like normal software. They fail semantically: wrong context, weak grounding, incomplete answers, and slow quality drift. Traditional monitoring cannot catch those failures alone.
A RAG evaluation harness gives teams a quality system that works across development and production. It makes each change measurable. It gives leadership confidence that the system can improve without silently weakening. Most importantly, it keeps the team focused on the right question: not “is the service running?” but “is the answer reliable?”
Get Quality Signals That Actually Reflect RAG Performance
GenAI Protos designs evaluation-first RAG systems for enterprise engineering teams. Build the quality layer before production users become the monitoring system.
Start the conversation



