Introduction
An LLM feature can return 200 OK responses all day and still damage trust. The server is healthy. The answer is not.
That is the production gap traditional monitoring cannot close. Standard APM tools are designed to detect runtime problems: latency, errors, memory, CPU, throughput. LLM and RAG systems fail at another layer. They retrieve the wrong context, generate unsupported claims, drift after prompt updates, or become less useful as user queries change.
LLM observability gives teams visibility into this quality layer. It helps engineering leaders answer a more useful question: not only “is the application up?” but “is the AI response still reliable?”
For RAG-heavy systems, this connects naturally to GenAI Protos’ RAG Applications expertise, where grounded answers and secure enterprise context are core requirements.
Business impact: Without LLM observability, users become the monitoring system. Quality failures show up as support tickets, low adoption, manual verification, and slower incident response. For leaders, the risk is not just a bad answer; it is the absence of evidence about when quality changed, which workflow was affected, and what release caused the issue.
Why Standard Monitoring Misses AI Failures
Traditional monitoring can confirm that a service is responding. It cannot confirm that an LLM answer is accurate, grounded, or relevant.
This creates four blind spots.
1. Output quality degradation
The response is delivered successfully, but it includes unsupported claims or misses the user’s actual intent.
2. Retrieval drift
The retriever still returns documents, but they are less relevant than before. This can happen after index changes, document updates, metadata changes, or shifts in user questions.
3. Prompt and context drift
A small prompt change can alter model behavior. A growing document corpus can increase context window pressure. Neither event necessarily triggers infrastructure alerts.
4. Compound failures
A weak retrieval leads to poor context, which leads to hallucination, which leads to user abandonment. Each step may look acceptable alone, but the full user experience fails.
The practical rule: green infrastructure dashboards do not equal a healthy AI system.
The Five Signal Layers
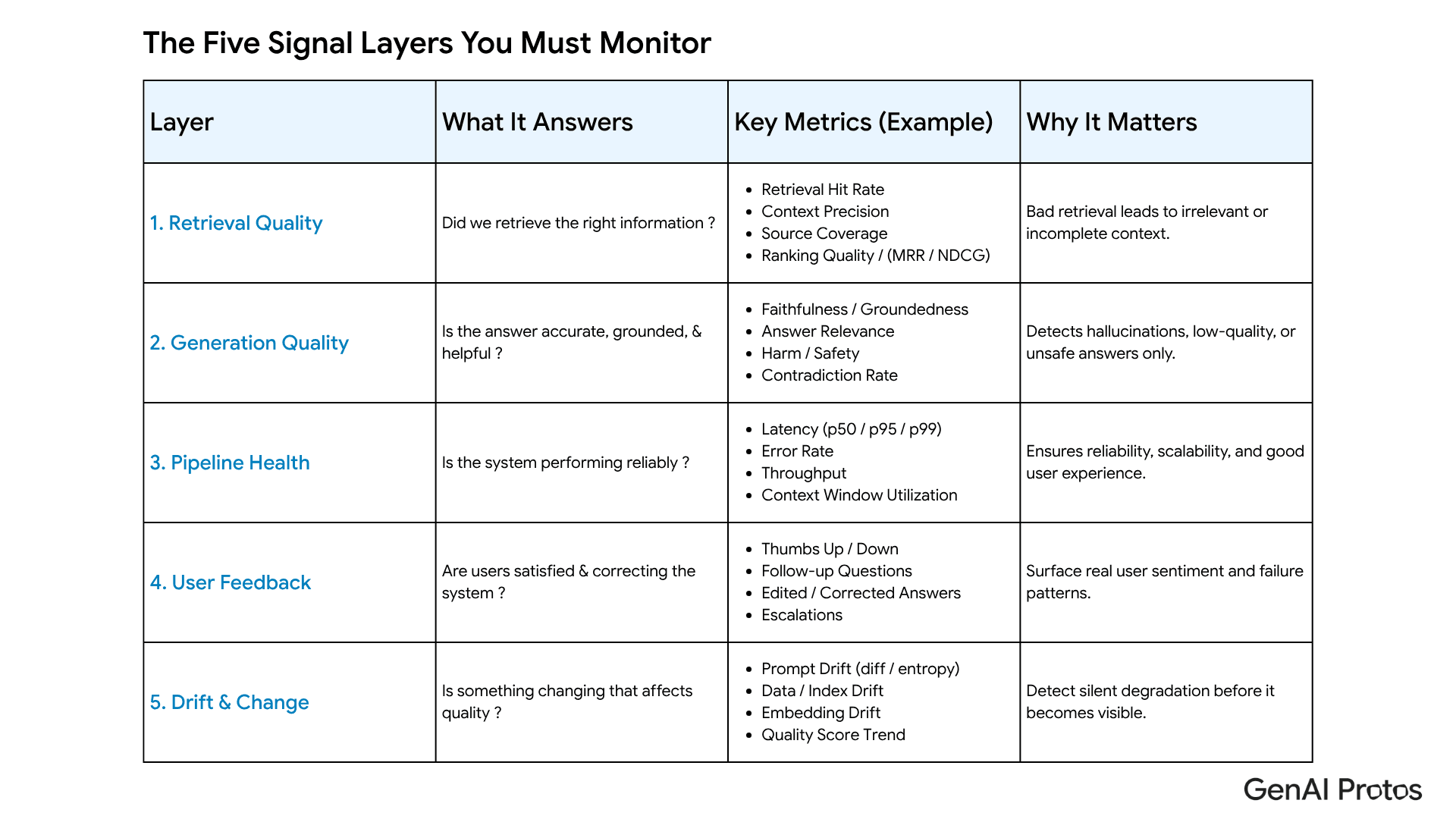
A useful LLM observability stack tracks five signal layers.
Retrieval quality
For RAG systems, retrieval quality sets the ceiling for answer quality. Track whether the correct sources are retrieved and whether they appear high enough in the result set to affect the answer.
Generation quality
Monitor whether the answer stays supported by retrieved content. A fluent response is not enough. The question is whether the system can justify what it says.
Pipeline health
Token cost, stage-level latency, and context window utilization help teams prevent operational issues before they become product issues.
User feedback
Automated scores are useful, but user behavior tells a different story. Repeated rephrasing, “not helpful” ratings, and session abandonment are strong indicators of poor value.
Prompt and context drift
Every prompt update, model change, index update, or corpus expansion should be treated as a production event. Observability should make those events visible.
For readers who need the RAG quality foundation, link to GenAI Protos’ guide on how RAG systems work.
The Observability Architecture
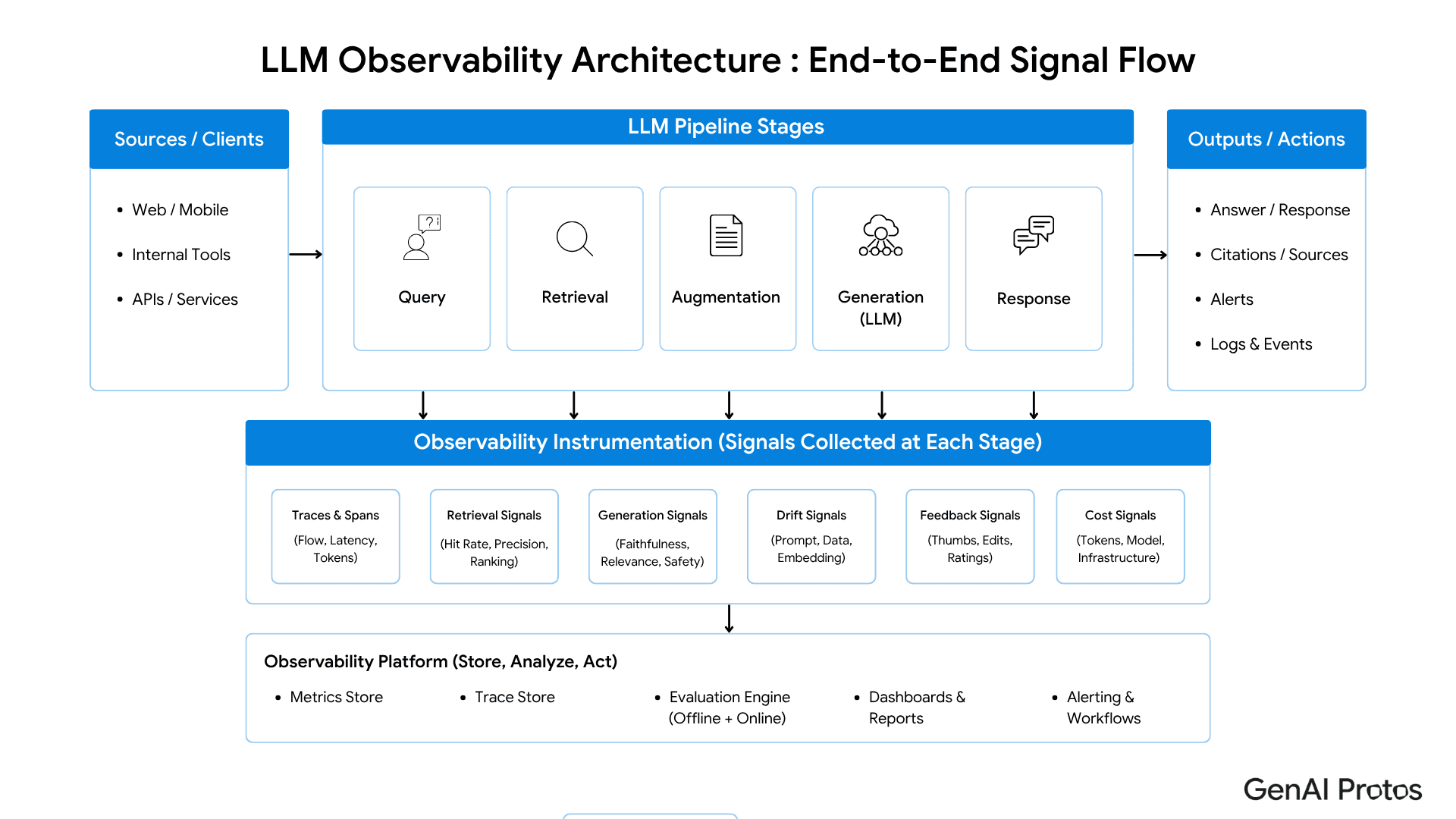
A complete architecture has five components.
1. Tracing
Capture the full path of a request:
user query
retrieval call
selected sources
prompt construction
model response
post-processing
delivery
The trace should connect quality scores back to the stage that caused the issue.
2. Evaluation
Run automated scoring on a defined sample of requests. Score retrieval relevance, faithfulness, groundedness, and answer relevance. Do not treat these scores as perfect truth. Treat them as leading indicators.
Operating benchmark: Trace every production request, score a representative sample by workflow, and review the highest-volume failure clusters during the first 30 to 60 days after launch. This gives teams enough visibility to separate isolated bad answers from systematic drift.
3. Feedback capture
Collect explicit and implicit signals from users. Useful AI systems improve when feedback flows into the product and engineering loop.
4. Drift detection
Track metric distributions over time. Alert on meaningful shifts, not only hard failures. Quality often degrades gradually.
5. Review dashboards
Dashboards should not stop at averages. Segment quality by workflow, query type, data source, prompt version, and user group.
What It Catches in Production
Silent retrieval decline
A document reindexing change may preserve uptime but weaken retrieval quality for a class of queries. Observability catches falling relevance before users complain.
Context window saturation
As documents get longer or chunk counts grow, the context window can become crowded. The system may truncate useful evidence and increase hallucination risk. Context utilization exposes this early.
Model or prompt update drift
A prompt or model update may change answer style, structure, or grounding behavior. If quality scores shift after the update, the team can investigate quickly.
GenAI Protos’ FactPulse fact-checking solution is a useful internal example because it demonstrates claim verification and evidence comparison patterns that also inform LLM quality monitoring.
Challenges Teams Underestimate
No ground truth
Automated quality scores are approximations. Validate them against human review.
Evaluation cost
Scoring every request can be expensive. Use sampling and segment coverage.
Telemetry overhead
Tracing should not slow the critical path. Use asynchronous export where possible.
Metric gaming
Teams can optimize for scores without improving user value. Pair automated scores with user signals.
Organizational resistance
Observability exposes uncomfortable quality gaps. Treat it as improvement infrastructure, not blame infrastructure.
For broader production delivery risks, GenAI Protos’ article on AI project delivery mistakes is a relevant internal link.
Key Takeaways
LLM observability must monitor semantic quality, not only infrastructure.
Retrieval quality is a first-order signal in RAG systems.
Context window utilization is a high-value early warning metric.
Prompt and model changes should be treated as production events.
Feedback loops connect quality dashboards to actual user value.
Conclusion
Production AI needs observability that can see what users experience. CPU, latency, and uptime are necessary, but they do not show whether an answer is faithful, useful, or grounded.
The right observability stack gives teams confidence to improve systems continuously. It makes prompt changes safer, model updates measurable, and retrieval issues diagnosable. Most importantly, it turns quality from an opinion into an operating signal.
Instrument Your LLM System for Quality From Day One
GenAI Protos builds quality-aware instrumentation into RAG and LLM systems so failures surface in dashboards instead of support tickets.
Start the conversation



