Most enterprise teams have seen reasoning models perform well in a demo environment.
Fewer have run both reasoning models and standard LLMs against their actual production task distribution and measured the outcome on real queries. That is where the selection decision becomes genuinely complicated.
Reasoning models are now accessible to any engineering team, but accessibility does not equal fit. The question is not which model type is more capable on an abstract benchmark. It is which model produces better task outcomes on your specific workload, at a cost and latency your production architecture can actually sustain.
Chain of Thought Prompting vs Reasoning Models: Key Differences
Standard LLMs can be instructed to work through a problem before producing an answer. Chain of thought prompting is the technique that makes this possible: you structure the prompt to ask the model to reason step by step, and the model works through the logic in its visible output before committing to a response.
This works well on many task types and closes a meaningful accuracy gap. The constraint is structural. In a standard LLM, the chain of thought is part of the output itself. The model generates each reasoning step as it writes. It cannot revise earlier reasoning before delivering the response.
Reasoning models operate differently. They run an internal thinking process that is not part of the visible output. That internal pass allows the model to check its own intermediate conclusions, identify contradictions in its logic, and change course before any output is committed. The visible response only appears after that internal revision is complete.
For tasks where a single incorrect reasoning step early in the chain compounds into a wrong final answer, this internal correction loop is the specific mechanism that drives the accuracy difference. For tasks where a prompted standard LLM is sufficient, upgrading to a reasoning model adds cost and latency with no meaningful gain.
When Prompt Engineering Is Enough: Standard LLM Use Cases
Standard LLMs handle the large majority of enterprise AI workloads effectively. The pattern across these tasks is single-pass output: the model reads input, applies retrieval or classification logic, and produces an answer without needing to hold competing constraints or run internal consistency checks.
Document summarization and extraction, classification and routing tasks like intent detection and ticket triage, structured data parsing from contracts and invoices, RAG-based response generation where the retrieval step handles the reasoning, and first-draft generation for reports or code scaffolding all fit this category.
For these task types, a standard LLM with well-designed prompt engineering will match or exceed a reasoning model on output quality at significantly lower inference cost and at a fraction of the latency. That combination is not a minor operational detail. A standard LLM pipeline can handle most user-facing queries at sub-second response times. The same workload on a reasoning model requires several seconds per response and inference cost increases that make the architecture difficult to sustain at production scale.
If your task does not require error correction across multiple sequential reasoning steps, a standard LLM with thoughtful prompt engineering is the better architecture. Not a compromise: the correct engineering decision.
Standard LLM vs Reasoning Model: At a Glance
| Criteria | Standard LLM | Reasoning Model |
|---|---|---|
| Best Use Case | Extraction, classification, summarization, RAG generation | Multi-step constraint tasks: code debugging, contract analysis, agent planning |
| Inference Cost | Low (baseline) | High (10x to 40x planning range) |
| Response Latency | Fast, typically under 1 second | Slower, several seconds per query |
| Prompt Engineering Impact | High: well-designed prompts close most accuracy gaps | Low incremental: accuracy ceiling set by internal reasoning loop |
| User-Facing Apps | Yes, sub-second responses | With care: async/streaming required above 2 seconds |
When Reasoning Models Are Worth the Cost: 4 Enterprise Use Cases
Reasoning models earn their cost on a specific category of tasks. The common thread: the correct answer requires the model to hold multiple constraints simultaneously, identify contradictions between them, and produce output only after verifying internal consistency. For enterprise AI deployments handling complex workloads, identifying which task classes cross this threshold is the core model selection decision.
Code generation and debugging across multiple files. The output must satisfy several interdependent requirements, and errors in one function propagate across the codebase. A reasoning model checks these dependencies before committing to output. A standard LLM generates code that looks correct and fails integration.
Long-context legal and contract analysis. The task is identifying clause conflicts or flagging obligations that contradict each other across hundreds of pages, not extracting what is explicitly stated. The multi-step constraint checking is what the reasoning model handles.
Agent task sequences involving five or more steps. The agent must plan a correct sequence of actions, detect when an intermediate step returns an unexpected result, and adapt without losing the overall goal. Errors at step two that go uncorrected compound through every subsequent step.
Multi-step scenarios with branching logic and consistency requirements. Conditions that must hold simultaneously across several calculations need to be verified, not assumed. A reasoning model can identify where those conditions conflict before producing an answer.
When Reasoning Models Are Not the Answer
Extraction and summarization tasks: If the task is retrieving or restating what is explicitly stated in a document, a standard LLM handles this correctly and returns results significantly faster.
Real-time user-facing generation: If the response must arrive in under one second, a reasoning model latency profile makes it the wrong architectural choice regardless of accuracy.
High-volume classification and routing: Intent detection and ticket triage run at high throughput with low per-query cost requirements. The cost and latency overhead of a reasoning model breaks the economics at scale.
The practical test: if a domain expert would need to work through the problem carefully in multiple steps before answering, evaluate a reasoning model against your actual task distribution. If the expert could answer immediately from pattern recognition, a standard LLM is almost certainly sufficient.
Enterprise AI Cost, Accuracy, and Latency: What to Plan For
Every model selection decision for production involves three variables that cannot all be optimized simultaneously.
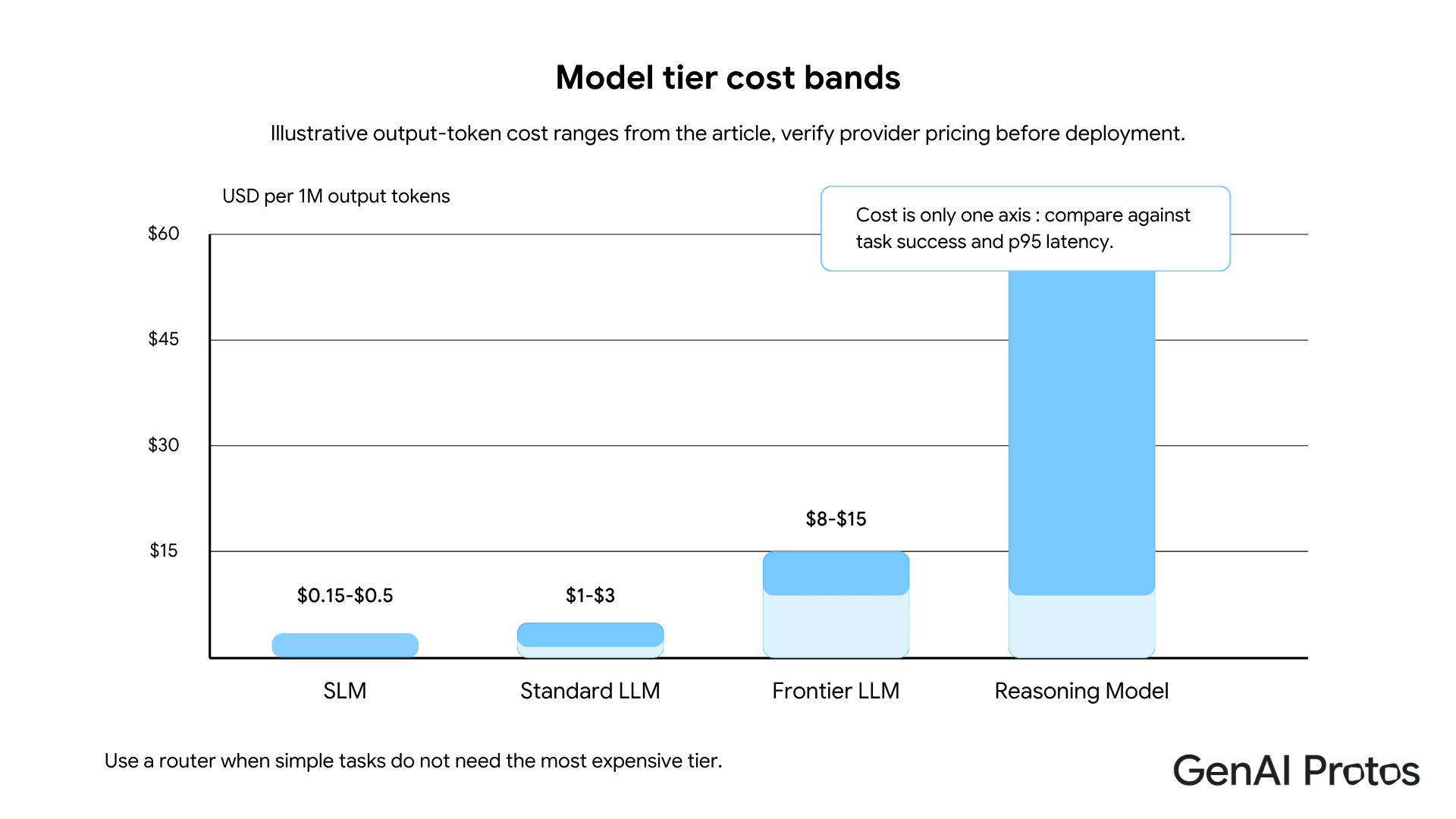
Cost scales significantly with model tier. Reasoning models run at substantially higher per-token inference cost than standard LLMs. Observed ranges across providers fall roughly 10x to 40x above standard LLM tiers, depending on provider and configuration. Treat these as planning ranges, not guarantees. At production query volumes, this difference determines whether an architecture is financially viable to operate, not just technically capable.
Accuracy gains are real but conditional. On task types where reasoning models outperform, the accuracy lift can be meaningful. Observed evaluations on constraint-heavy tasks show ranges of 10 to 25 percentage points on task success rate, though results vary by task type and evaluation setup. For tasks where chain of thought prompting on a standard LLM already meets your accuracy threshold, adding a reasoning model increases cost without improving outcomes. On tasks outside those categories, the gain typically falls within prompt engineering variance: a better-designed prompt on a standard LLM would have closed the same gap at no additional model cost.
Latencydetermines interaction design. Standard LLMs return most responses in under one second. Reasoning models return responses in several seconds depending on problem complexity. For user-facing applications, responses above two seconds require async handling, progress indicators, and streaming to remain usable. For background batch pipelines, latency is a smaller constraint.
The common mistake: evaluating model accuracy in isolation and ignoring cost and latency until they surface as production problems. The model that performs best on a 50-task demo evaluation does not automatically produce a sustainable architecture at scale.
How to Build an Enterprise AI Model Routing Strategy
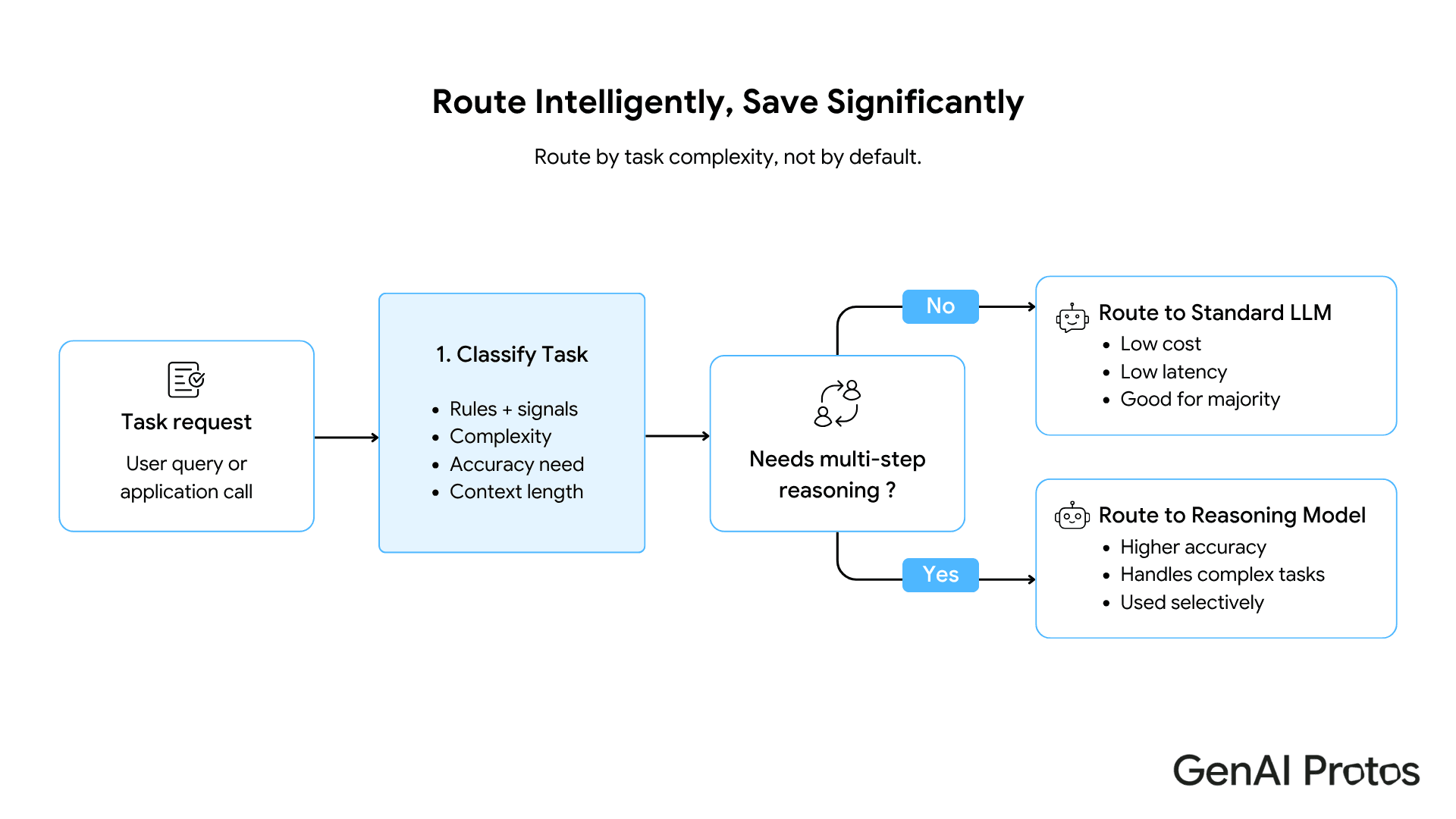
The architecture that holds at production scale is not a single model tier applied to all tasks. It is a router: a lightweight classifier that identifies the complexity profile of each incoming request and routes it to the appropriate model tier.
Simple, single-pass tasks route to a standard LLM with a well-configured prompt. Complex, multi-step constraint tasks route to a reasoning model. The router itself is fast and inexpensive to operate.
This routing layer is not a premature optimization. For any enterprise deployment handling a mix of task types, routing reduces per-query inference cost significantly because the majority of tasks, even in sophisticated AI products, fall into the category that a well-prompted standard LLM handles correctly. The cost savings from routing simple tasks to a standard LLM fund the reasoning model capacity for the tasks that actually need it.
Before building the router, establish your evaluation baseline. Run both model tiers against 50 to 100 real tasks from your production distribution. Not benchmark tasks. Not vendor demo tasks. Tasks that represent what your system will actually be asked.
Measure task success rate and cost per successful task completion separately. Map which task categories cross the threshold where the accuracy gain from a reasoning model justifies its cost premium. Route those task classes to a reasoning model. Route everything else to a standard LLM.
The teams that build sustainable enterprise AI architectures are the ones who measured before they committed, not after they received the inference cost bill.



